Im zweiten Teil des Git Tutoriums wurde ein Überblick über das Branching-Modell gegeben. Dieser dritte Teil rundet den Einstieg in Git ab, womit man für die gängigsten Aufgaben gewappnet sein sollte. Dies umfasst zum einen das Rebasing und zum anderen das Arbeiten mit Remote-Repositorys.
Dieses Tutorium besteht aus vier Teilen. Wem das Tutorium gefällt und mehr über Git lernen möchte, der kann sich das Buch „Versionsverwaltung mit Git“ für 29,99€ bestellen. In diesem Buch, was ich geschrieben habe, werden die Themen rund um Git noch deutlich ausführlicher behandelt.
Rebasing
Das Rebasing gehört ebenfalls zum Branching-Modell von Git. Im vorherigen Teil des Tutoriums wurde Branches mit dem “git merge” Befehl zusammen geführt. Eine andere Art der Zusammenführung von Branches ist das Rebasing.
Beim normalen Mergen werden beide Branches zusammen geführt und gegebenenfalls ein Merge-Commit erzeugt. Anders sieht es beim Rebasing aus. In diesem Fall werden die Commits aus einem Branch einzeln auf dem Haupt-Branch angewendet. Ein Unterschied zum normalen Merge ist, dass in der Historie des Repositorys beziehungsweise des Branches keine der vorherigen angelegten Branches mehr sichtbar sind.
Um die Funktionsweise besser zu erläutern und zu verstehen, folgt das erste Beispiel, wofür wieder jeweils ein Commit auf zwei Branches gebraucht werden. Zunächst muss man sicherstellen, dass man auf dem Branch “master” befindet, von dem man dann den zweiten Branch namens “more_content” anlegt.
$ git checkout master
$ git checkout -b more_content
Auf diesen Branch muss man nun in der Datei “index.html” ein wenig mehr Inhalt hinzufügen. Dazu reicht es etwa den Lorem-Ipsum Text in den “<p>"-Tag zu verdreifachen. Die Änderung kann dann wieder wie gewohnt commitet werden.
$ git add index.html
$ git commit -m "Verdreifachung des Lorem-Ipsum-Texts"
[more_content 609f8a4] Verdreifachung des Lorem-Ipsum-Texts
1 file changed, 6 insertions(+)
Einen Commit auf dem Branch “more_content” gibt es an dieser Stelle somit auch schon. Jetzt muss man zunächst mit dem Befehl “git checkout master” wieder zurück auf den Branch “master” wechseln und dort einen Commit erzeugen.
In der index.html kann man nun für den ersten Commit in der Navigation folgende Zeile verdreifachen:
<li><a href="#">Link</a></li>
Anschließend kann man den ersten Commit tätigen:
$ git add index.html
$ git commit -m "Navigation um zwei Links erweitert."
[master 8d8d6ce] Navigation um zwei Links erweitert.
1 file changed, 2 insertions(+)
Im zweiten Teil dieser Artikel-Reihe hätten wir an dieser Stelle einen Merge gemacht. Konkret würde bei einem “git merge more_content” der eine Commit aus dem Branch “more_content” in den Branch “master” gemergt und es würde zusätzlich ein weiterer Merge-Commit entstehen.
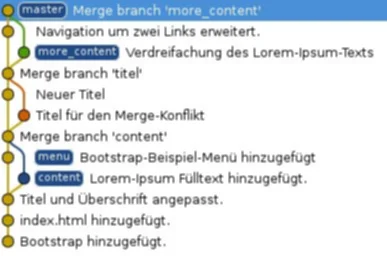
Den Merge-Commit möchte man beim Rebasen allerdings vermeiden. Ziel des Rebasing ist es, das man den ursprünglichen Entwicklungsbranch nicht mehr sieht und es dann aussieht wie ein gerader Entwicklungs-Strang. Hier stellt sich natürlich die Frage, was jetzt die genauen Vorteile und auch Nachteile vom Rebasen gegenüber dem Mergen ist. Wie bereits oben im Text erwähnt, werden die Commits einzeln auf dem Branch neu angewendet. Die genaue Funktion wird klarer, wenn man es einmal durchgeführt hat. Hierfür wechselt man zunächst zurück auf den Branch “more_content” und macht dort den Rebase.
$ git checkout more_content
$ git rebase master
Zunächst wird der Branch zurückgespult, um Ihre Änderungen
darauf neu anzuwenden...
Wende an: Verdreifachung des Lorem-Ipsum-Texts
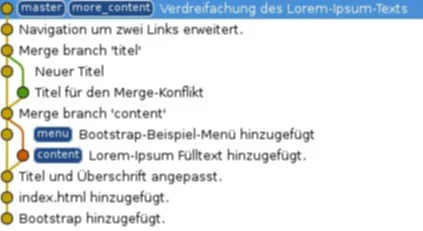
Wenn man also auf dem Branch “more_content” ist und die Änderungen aus dem Branch “master” übernehmen möchte ohne einen Merge-Commit zu haben, dann muss man “git rebase master” ausführen. Wie man aus der Terminal-Ausgabe ablesen kann, wird der Branch zunächst “zurückgespult”, das heißt, dass in diesem Schritt vorübergehen die gemachten Änderungen vorübergehend zurück genommen werden. Anschließend übernimmt Git die Commits aus dem anderen Branch, in diesem Fall aus dem Branch “master”. Zum Schluss werden die Commits vom Branch einzeln wieder angewandt. Da es sich in diesem Beispiel um lediglich einen Commit handelt, wird auch nur dieser angewandt.
Klarer wird es, wenn man sich die Commits auf einem Branch als einen Stapel vorstellt. Beim Rebase wird auf “more_content” sozusagen jeder Commit vom Stapel genommen, bis es einen gemeinsamen Commit vom Branch “master” gefunden hat. An diesem Punkt werden dann die neuen Commits von “master” wieder auf “more_content” gestapelt. Anschließend werden die vorläufig entfernten Commits auf “more_content” wieder einzeln auf den Commit-Stapel gelegt.
Jetzt lohnt sich ein Blick in das Log. Relevant sind lediglich die letzten drei Commits, weshalb man mit dem Parameter “-n 3” auch ausschließlich die drei neuesten Commits auf dem aktuellen Branch anschauen kann.
$ git log -n 3
commit 27bf2ae348279599cfa67fd0631e7f3e5c90840d
Author: Sujeevan Vijayakumaran <mail@svij.org>
Date: Sun Jan 4 19:03:23 2015 +0100
Verdreifachung des Lorem-Ipsum-Texts
commit 8d8d6ce271ddf776def806bbe65c1439c84f8c67
Author: Sujeevan Vijayakumaran <mail@svij.org>
Date: Sun Jan 4 19:12:42 2015 +0100
Navigation um zwei Links erweitert.
commit aa2fbe6716f743d434a0f7bec9b97548304338c8
Merge: b967fa1 b6781c8
Author: Sujeevan Vijayakumaran <mail@svij.org>
Date: Sun Jan 4 15:54:15 2015 +0100
Merge branch 'titel'
Conflicts:
index.html
Im Git Log steht oben immer der neueste Commit auf dem Branch. Wer jetzt allerdings genau hinsieht, der merkt, dass der oberste Commit um 19:03 Uhr getätigt wurde und der Commit darunter um 19:12 Uhr. Zeitlich betrachtet ist also der vorletzte Commit der neueste Commit, während der echte neueste Commit zeitlich vorher erzeugt wurde. Dies ist eine Eigenschaft, die genau dann beim Rebasen zustande kommt. In der Historie eines Git-Repositorys sind die Commits nämlich immer in logische Reihenfolge und diese ist nicht zwangsläufig auch die zeitlich richtige Reihenfolge. Es stellt sich für viele vermutlich an dieser Stelle die Frage: Warum brauche ich das?
Beim Entwickeln von Software werden häufig einzelne Features gleichzeitig entwickelt. Wenn etwa der Branch “master” nur vollständige und somit fertige Features enthält, dann werden dort immer nur die Änderungen zusammengeführt, wenn die Branches fertig sind. Wenn man allerdings an einem größeren Feature entwickelt, welches durchaus längere Zeit braucht, dann zweigt man beispielsweise vom Branch “master” ab und entwickelt für eine Zeit dort sein Feature. Über die Zeit hinweg läuft allerdings auch die Entwicklung auf dem Branch “master” weiter, was heißt, dass diese beidem Entwicklungszweige gegebenenfalls immer stärker divergieren. Ein konflikt-freies Mergen beider Branches nach längerer Entwicklungszeit ist dann gegebenenfalls nicht mehr so einfach möglich. Wenn man dann auf dem Entwicklungsbranch ein Rebase durchführt, dann sind da auch alle Änderungen von “master” enthalten. Dieses Vorgehen auch dann sinnvoll, wenn der Entwickler auf dem Entwicklungsbranch die Änderungen aus “master” braucht. Unschön wäre hier ein Merge, da man in der Historie bei mehrmaligen Mergen von “master” diverse Merge-Commits besitzt, die man durch das Rebasen einfach vermeiden kann.
Nach dem Rebase möchte man die Änderungen vom Branch “more_content” letztendlich auch in “master” übernehmen. Hierfür reicht dann wieder ein normaler Merge:
$ git checkout master
$ git merge more_content
Aktualisiere 8d8d6ce..27bf2ae
Fast-forward
index.html | 6 ++++++
1 file changed, 6 insertions(+)
Der Merge ist dann ein Fast-Forward Merge. Wenn man nun erneut in das Git Log von “master” schaut, dann sieht man keinerlei Informationen mehr von der Existenz des Branches “more_content”. Rebasing lohnt sich also auch für Experimentier-Branches, dessen Namen man hinterher nicht mehr in der Historie lesen möchte.
Zum Schluss stellt sich noch die Frage, wann man Rebasen und wann man Mergen sollte. Als kleine Grundregel kann man sich merken, dass man immer dann Rebasen sollte, wenn man zeitgleich laufende Änderungen regelmäßig aus einem anderen Branch auch in seinem eigenen Entwicklungsbranch reinholen möchte. Ein Merge sollt man hingegen dann tun, wenn man fertige Entwicklungsbranches in einen der Hauptentwicklungsbranches zusammenführen möchte. Weder das eine noch das andere lässt sich problemlos jedes Mal durchführen, sodass es häufig auch auf die jeweilige Situation ankommt, ob man nun rebased oder mergt.
Remote-Repositorys
Eine weitere große Stärke von Git ist, dass man ein Repository auf vielen verschiedenen Rechnern verteilen kann. Es ist daher ein verteiltes Versionsverwaltungsprogramm. Ein vollständiges Git-Repository kann an vielen verschiedenen Orten liegen.
Diejenigen, welche das Git-Repository mit den zuvor angegebenen Befehlen angelegt haben, besitzen zur Zeit nur ein lokales Repository. Wichtig für das Verständnis ist, dass in der Theorie jedes Git-Repository mit jedem gleichgestellt ist. In der Praxis sieht das allerdings etwas anders aus, da bei den meisten Projekten mit einem zentralen Server gearbeitet wird.
Entfernt liegende Repositorys nennt man Remote-Repositorys. Um mit eben diesen zu arbeiten, gibt es den Befehl “git remote”. Wenn keine Remote-Repositorys hinzugefügt worden sind, wie bei diesem Beispiel-Repository, dann erfolgt keine Ausgabe beim Ausführen des Kommandos. Es bietet sich grundsätzlich immer an, mit Remote-Repositorys zu arbeiten. Ein Projekt, dessen Git-Repository nur auf einem lokalen Rechner liegt, ist kaum vor Ausfällen gesichert. Remote-Repositorys sind insbesondere deshalb nützlich, da man damit einfach kollaborativ arbeiten kann.
Um die Arbeitsweise mit Remote-Repositorys zu verstehen und zu erlernen, werden zunächst einige Remote-Repositorys angelegt, die auf dem lokalen Rechner liegen. In einem Projekt mit mehreren Personen gibt es meist ein zentrales Repository für das gesamte Projekt sowie einzelne Repositorys für die jeweiligen Projekt-Mitarbeiter.
Man nehme also an, dass es in diesem Beispiel-Webseiten-Projekt zwei Mitarbeiter gibt: “Ich” und “Er”. Dazu wechselt man erst in den Projektordner “Webseite-mit-Git”, anschließend legt man die entsprechenden Repositorys an:
$ mkdir ~/Git
$ git clone --bare . ~/Git/Webseite-mit-Git.git
Klone in Bare-Repository '/home/sujee/Git/Webseite-mit-Git.git'...
Fertig.
$ git clone --bare . ~/Git/Er.git
Klone in Bare-Repository '/home/sujee/Git/Er.git'...
Fertig.
$ git clone --bare . ~/Git/Ich.git
Klone in Bare-Repository '/home/sujee/Git/Ich.git'...
Fertig.
Der Befehl “git clone” klont, also kopiert, das ganze Repository. Es nimmt in diesem Fall das aktuelle Projekt und speichert es dann in unter dem lokalen Pfad “~/Git/”. Der Inhalt aller Ordner sind zu Beginn identisch und enthalten das “.git”-Verzeichnis des Projekts.
Hinweis: Das oben erläuterte Anlegen von Repositorys ist keine alltägliche Form, die einen in der Praxis erwartet. Dies dient lediglich dazu, das Arbeiten mit Remote-Repositorys zu erläutern, was auch geht, wenn die Repositorys lokal auf dem Rechner liegen. In der Regel setzt man eigene Git-Server-Dienste auf oder nutzt externe Dienste wie GitHub oder Bitbucket, wo man sowohl private als auch öffentliche Repositorys anlegen kann. Auf eine genauere Anleitung wird an dieser Stelle zunächst verzichtet, um den Rahmen des Tutoriums nicht zu sprengen.
Jetzt ist es an der Zeit die Remote-Repositorys mit dem Projekt zu verbinden. Im Projekt-Ordner “Webseite-mit-Git” fügt man also zunächst sein privates Repository als Remote hinzu.
$ git remote add origin ~/Git/ich.git
Dieses Kommando setzt sich aus mehreren Teilen zusammen. Der Parameter “remote” bezieht sich auf Remote-Repository-Feature von Git. Mit “add” gibt man an, das man ein Remote-Repository hinzufügen möchte. Der Parameter “add” verlangt wiederum zwei Parameter, das wäre zum einen der Name und zum anderen der Pfad zum Repository. Der Pfad zum entfernten Repository kann auch über SSH, HTTPS oder über das Git-Protokoll erfolgen. Das eigene Repository wird in der Regel “origin” genannt, dort sollte man auch volle Schreib-Rechte besitzen.
Weiterhin bietet es sich nun an, die übrigen Remote-Repositories hinzuzufügen, das wären “upstream” und “er”. Das Repository “upstream” soll das gemeinsame Repository beider Mitarbeiter sein, auf dem die fertige Webseite kollaborativ erarbeitet werden soll:
$ git remote add upstream ~/Git/Webseite-mit-Git.git
$ git remote add er ~/Git/Er.git
Der Befehl “git remote” sollte nun drei Remotes anzeigen.
$ git remote
er
origin
upstream
Bis jetzt wurde Git nur bekannt gegeben, dass es diese Remote-Repositorys gibt. Die Inhalte wurden noch nicht in das lokale Repository heruntergeladen. Um dies zu erledigen, gibt es das Git-Kommando “fetch”. Damit kann man die Bestandteile eines Remote-Repositorys herunterladen.
$ git fetch upstream
Von /home/sujee/Git/Webseite-mit-Git
* [neuer Branch] content -> upstream/content
* [neuer Branch] master -> upstream/master
* [neuer Branch] menu -> upstream/menu
* [neuer Branch] more_content -> upstream/more_content
Wie man aus der Ausgabe herauslesen kann, wurde die Branches “master”, “content” und “menu” und “more_content” vom Repository “upstream” heruntergeladen. Da es mühselig wäre, für jedes Remote-Repository einzeln “git fetch” aufzurufen, gibt es auch eine Möglichkeit, alle Remote-Repositories in einem Rutsch herunterzuladen:
$ git remote update
Fordere an von upstream
Fordere an von er
Von /home/sujee/Git/Er
* [neuer Branch] content -> er/content
* [neuer Branch] master -> er/master
* [neuer Branch] menu -> er/menu
* [neuer Branch] more_content -> er/more_content
Fordere an von origin
Von /home/sujee/Git/ich
* [neuer Branch] content -> origin/content
* [neuer Branch] master -> origin/master
* [neuer Branch] menu -> origin/menu
* [neuer Branch] more_content -> origin/more_content
Alternativ kann man auch “git fetch –all” ausführen, welches denselben Effekt hat.
Die Remote-Repositories sind nun vollständig konfiguriert und liegen auch lokal im Projekt-Ordner. Praktisch ist jetzt, dass man zwischen den einzelnen Branches der Repositories wechseln kann.
Mittlerweile wurden zwar einige Remote-Repositorys hinzugefügt, allerdings kann man durchaus die vergebenen Namen nachschlagen. Es reicht lediglich folgenden Befehl auszuführen:
$ git remote
er
origin
upstream
Wenn man eine ausführlichere Ausgabe möchte, etwa die Adresse des Remote-Repositorys, dann kann man dem Befehl den Parameter “-v” übergeben.
$ git remote -v
er /home/sujee/Git/Er.git (fetch)
er /home/sujee/Git/Er.git (push)
origin /home/sujee/Git/Ich.git (fetch)
origin /home/sujee/Git/Ich.git (push)
upstream /home/sujee/Git/Webseite-mit-Git.git (fetch)
upstream /home/sujee/Git/Webseite-mit-Git.git (push)
Zum aktuellen Zeitpunkt ist sowohl das lokale als auch die entfernten Repositorys auf demselben Stand.
Jetzt ist es notwendig, einen weiteren Commit zu tätigen. In diesem Beispiel nummeriert man einfach alle Links in der Navigation aus der Datei “index.html”. Sodass man hinterher in der Navigation nicht mehr 4x “Link” stehen hat, sondern “Link 1” bis “Link 4”. Anschließend erzeugt wieder einen Commit mit dieser Änderung.
$ git add index.html
$ git commit -m "Links in der Navigation durchnummeriert."
[master 59b89eb] Links in der Navigation durchnummeriert.
1 file changed, 4 insertions(+), 4 deletions(-)
Jetzt ist zwar ein Commit angelegt worden, diesen möchte man allerdings noch in das entfernt liegende Repository pushen. Dies ist ein gängiges Prozedere, um die Änderungen online zu bringen, etwa um mit anderen zu kollaborieren oder um seine Arbeiten zu sichern.
Jetzt könnte man direkt den Push-Befehl ausführen:
$ git push
fatal: Der aktuelle Branch master hat keinen Upstream-Branch.
Um den aktuellen Branch zu versenden und den Remote-Branch
als Upstream-Branch zu setzen, benutzen Sie
git push --set-upstream origin master
Wenn man “git push” ohne jeglichen Parameter ausführt, dann versucht Git den aktuellen Branch auf das Remote-Repository zu übertragen. Allerdings tut Git es nur, wenn ein Upstream-Branch gesetzt ist. Wie die Aussage oben aussagt, muss man hierfür einen Upstream-Branch einrichten.
$ git push --set-upstream origin master
Zähle Objekte: 3, Fertig.
Delta compression using up to 4 threads.
Komprimiere Objekte: 100% (3/3), Fertig.
Schreibe Objekte: 100% (3/3), 408 bytes | 0 bytes/s, Fertig.
Total 3 (delta 1), reused 0 (delta 0)
To /home/sujee/Git/Ich.git
27bf2ae..59b89eb master -> master
Branch master konfiguriert zum Folgen von Remote-Branch master von origin.
Der Parameter “–set-upstream” lässt sich ebenfalls in einer kürzeren Variante ausführen, dies ist dann schlicht der Parameter “-u”.
Der Befehl führt zwei Dinge aus: Zum einen pusht er der den Branch “master” zum Remote-Repository namens “origin” und zum anderen verknüpft Git den lokalen Branch mit dem Remote-Branch auf origin.

Wenn man nun nur noch “git push” ausführt, dann wird automatisch der aktuelle lokale Branch “master” nach origin übertragen, sofern Änderungen vorhanden sind.
$ git push origin master
Everything up-to-date.
Mittlerweile liegen im Repository vier Branches, wovon bereits alle Änderungen gemergt worden sind und keine mehr gebraucht werden. Diese lassen sich ganz einfach mit dem folgenden Befehl löschen:
$ git branch -d content
$ git branch -d menu more_content
Man kann das Löschen sowohl einzeln durchführen, oder auch gesammelt innerhalb eines Kommandos, wie es oben angegeben ist. Übrig bleibt lediglich der Branch “master”. Wichtig zu wissen ist, dass hiermit ausschließlich die lokalen Branches gelöscht worden sind. Wenn man nun auch noch auf dem Remote-Repository die Branches löschen möchte, muss man folgende Befehle ausführen:
$ git push origin --delete content
To /home/sujee/Git/Ich.git
- [deleted] content
$ git push origin :menu
To /home/sujee/Git/Ich.git
- [deleted] menu
$ git push origin --delete more_content
To /home/sujee/Git/Ich.git
- [deleted] more_content
Wie man sieht, gibt es zwei verschiedene Möglichkeiten Remote-Branches zu löschen, das wäre zum einen das “git push” Kommando mit dem Paramater “–delete” und dem Namen des Remote-Branches und zum anderen kann man mit “git push” auch mit einem Doppelpunkt vor dem Branch-Namen den Remote-Branch löschen. Klarer und deutlicher ist vorallem die erste Variante. Auch dieser Befehl lässt sich Zusammefassen, sodass man auch einfach folgenden Befehl hätte ausführen können:
$ git push origin :menu :more_content :content
Praktisch ist auch der folgende Befehl:
$ git remote show origin
* Remote-Repository origin
URL zum Abholen: /home/sujee/Git/Ich.git
URL zum Versenden: /home/sujee/Git/Ich.git
Hauptbranch: master
Remote-Branch:
master gefolgt
Lokaler Branch konfiguriert für 'git pull':
master führt mit Remote-Branch master zusammen
Lokale Referenz konfiguriert für 'git push':
master versendet nach master (aktuell)
Dieser zeigt alle relevanten Informationen von einem konfigurierten Remote-Repository an. Wenn man einen Namen von einem Remote-Repository lokal ändern möchte, kann man auch folgenden Befehl ausführen:
$ git remote rename er jemand
In diesem Fall wird dann der Name von “er” auf “jemand” geändert. Remote-Repositorys kann man auch einfach wieder entfernen:
$ git remote rm jemand
Der Befehl liefert im Erfolgsfall keine Ausgabe. An diesem Punkt ist wichtig zu wissen, dass nur die Verknüpfung im lokalen Repository gelöscht wird. Auf dem entfernt liegenden Server sind weiterhin die Daten vorhanden, sofern diese nicht schon vorher gelöscht worden sind.
Zum Schluss muss man nur noch das korrekte Arbeiten mit Remote-Branches verstehen. Nach der vorangegangenen Aufräumaktion sind noch zwei Remote-Repositorys übrig: origin und upstream. Auf origin befindet sich nur noch der Branch “master”, auf upstream befinden sich noch alle vier Branches, wobei dort “master” noch nicht auf dem aktuellen Stand ist.
Um “master” auch auf dem Remote-Repository namens “upstream” zu pushen, reicht folgender Befehl:
$ git push upstream
Zähle Objekte: 3, Fertig.
Delta compression using up to 4 threads.
Komprimiere Objekte: 100% (3/3), Fertig.
Schreibe Objekte: 100% (3/3), 408 bytes | 0 bytes/s, Fertig.
Total 3 (delta 1), reused 0 (delta 0)
To /home/sujee/Git/Webseite-mit-Git.git
27bf2ae..59b89eb master -> master
Da kein Branch-Name angegeben worden ist, wird der Branch gepusht, auf dem man sich gerade befindet.
Jetzt steht nur noch an, dass man einen bestimmten Branch von “upstream” lokal ausschecken möchte. Die Remote-Branches
folgen einem Muster, nämlich “
$ git checkout upstream/content
Note: checking out 'upstream/content'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b new_branch_name
HEAD ist jetzt bei e39da6e... Lorem-Ipsum Fülltext hinzugefügt.
Das Problem hier ist, dass man in einem anderen Zustand landet, der sich “detached HEAD” nennt. Wie der Text schon aussagt, ist es ein Zustand, in dem man zwar Commits machen kann, allerdings sind diese keinem Branch zugeordnet. Dies wird deutlich, wenn man “git branch” ausführt:
$ git branch
* (losgelöst von upstream/content)
master
Der Zustand ist allerdings weniger problematisch, da man sich einfach einen neuen Branch anlegen kann, basierend auf dem Branch upstream/content:
$ git checkout -b content
Zu neuem Branch 'content' gewechselt
So ist man nun wieder auf einen normalen Branch in einem normalen Zustand. Wenn man nun die Änderungen von einem Remote-Branch auch lokal haben möchte, kann man diese mit “git pull” herunterladen. Der Pull-Befehl ist das Gegenstück vom Push-Befehl.
$ git pull
There is no tracking information for the current branch.
Please specify which branch you want to merge with.
See git-pull(1) for details
git pull <remote> <branch>
If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to=<remote>/<branch> content
Wie auch beim ersten Push-Befehl, fehlt dem lokalen Branch die Verknüpfung, woher die Änderungen heruntergeladen werden sollen. Wenn man nur einmalig die Änderungen von upstream/content holen möchte, reicht “git pull upstream content” auszuführen. Wenn man hingegen häufiger aus demselben Branch vom selben Repository pullen möchte, dann bietet sich die oben aufgeführte zweite Variante an.
Fazit
In diesem Teil der Artikel-Reihe zu Git wurden erläutert was das Rebasen ist, wie es geht und warum man es nutzt. Weiterhin kann man jetzt mit Remote-Repositorys arbeiten und zwischen verschiedenen Remote-Repositorys pullen und pushen.