Zur Entwicklung von Software wird in der Regel ein Versionsverwaltungsprogramm genutzt. Es gibt zahlreiche Anwendungen um dies zu erledigen, zu den bekannteren Programmen gehören Subversion, CVS, Mercurial, Bazaar und eben Git. Dieser Artikel gibt einen Überblick über Git, was es ist, wie man es einsetzen kann und wie es funktioniert.
Hinweis: Einigen Lesern dürfte die erste Hälfte bekannt vorkommen. Dies erschien in ähnlicher Fassung bereits im ersten Teil des Git-Tutorials.
Was ist eine Versionsverwaltung?
Für die Leser, die noch keine Erfahrung oder Ahnung von Versionsverwaltungsprogrammen haben, ist es zunächst wichtig zu wissen, was denn genau ein solches Programm macht. Die Bedeutung einer Versionsverwaltung lässt sich schon fast aus dem Wort ableiten: Es handelt sich um das Verwalten von Versionen. Konkret heißt dies, dass man von Dateien Versionen erzeugen kann, die dann sinnvoll verwaltet werden. Einzelne Versionen beinhalten keineswegs nur große Änderungen, sondern sehr wohl auch kleinere Änderungen.
Viele kennen es: Man geht einer Tätigkeit nach – sei es an einem Text, einem Bild oder an einem Video – und man möchte den aktuellen Stand immer mal wieder zwischenspeichern, damit man zum einen eine Sicherung der Datei hat und zum anderen wieder auf eine ältere Version zurückspringen kann, wenn etwas falsch gelaufen ist. Jede Person hat dabei verschiedene Ansätze, die einzelnen Versionen irgendwo abzulegen. Die eine Person fügt jeweils eine Versionsnummer in den Dateinamen ein, eine andere Person macht sich wiederum einzelne Ordner für jede Version mit dem aktuellen Datum, in dem die einzelnen Stände gesichert werden. Wirklich praktikabel und effizient sind keine der beiden genannten Varianten, da sich sehr schnell und sehr einfach Fehler einschleichen, etwa wenn man alte Revisionen löscht, die man gegebenenfalls hinterher doch wieder braucht.
Genau hier kommen Versionsverwaltungssysteme ins Spiel. Mit einer Versionsverwaltung werden zusätzlich zu den reinen Veränderungen noch weitere Informationen zu einer Version gespeichert. Darunter fallen Informationen zum Autor, der Uhrzeit und eine Änderungsnotiz. Diese werden bei jedem Versionswechsel gespeichert. Durch die gesammelten Dateien lässt sich so schnell und einfach eine Änderungshistorie anzeigen und verwalten. Falls zwischendurch Fehler in den versionierten Dateien aufgetreten sind, kann man dann wieder zurück zu einer Version springen, um von dort aus erneut weiter zu machen. Dabei ist es ganz egal, um was für eine Art von Dateien es sich handelt. Am häufigsten werden Versionsverwaltungsprogramme zur Software-Entwicklung eingesetzt. Ein ziemlich ähnliches Konzept findet sich auch im Wiki von ubuntuusers.de. So besitzt jede Wiki-Seite ebenfalls eine Änderungshistorie, wie man es beispielsweise am Wiki-Artikel zu ubuntuusers selbst sehen kann.
Aber nicht nur für Programmierer ist eine Versionsverwaltung sinnvoll; wie bereits geschrieben, kann der Einsatz zum Beispiel auch für Grafiker oder Autoren durchaus nützlich sein. Ein Grafiker könnte sich so Versionen von bearbeiteten Bildern speichern, um bei misslungenen Änderungen wieder zurückspringen zu können. Bei Autoren geht es um Text, der ähnlich dem Quellcode von Software-Projekten gut verwaltet werden kann. Vor allem bei kollaborativen Arbeiten zahlt sich der Einsatz von Git oder einem anderen Versionsverwaltungsprogramm aus. Jeder Mitarbeiter kann so seine Änderungen einem Projekt hinzufügen und so kann sehr gut nachverfolgt werden, welche Person aus welchen Gründen und zu welcher Zeit eine Änderung durchgeführt hat. Dieser Vorteil spielt sich besonders bei Text-Dateien aus, da man hier Zeile für Zeile überprüfen kann, welche Änderungen gemacht worden sind.
Es gibt drei verschiedene Konzepte zur Versionsverwaltung: die lokale, zentrale und die verteilte Versionsverwaltung.
Lokale Versionsverwaltung
Die lokale Versionsverwaltung ist wohl eher selten in produktiven Umgebungen zu finden, da sie lediglich lokal arbeitet und häufig auch nur einzelne Dateien versioniert. Das oben bereits erwähnte manuelle Erzeugen von Versionen von Dateien wäre zum Beispiel eine lokale Versionsverwaltung mit einer einzelnen Datei. Sie ist zwar ziemlich einfach zu nutzen, allerdings resultiert daraus eine hohe Fehleranfälligkeit und sie ist zudem wenig flexibel. Echte lokale Versionsverwaltungssoftware gibt es mit SCCS und RCS auch. Der wohl größte Minuspunkt der lokalen Versionsverwaltung ist, dass man standardmäßig nicht mit mehreren Personen an Dateien arbeiten kann. Außerdem besteht keinerlei Datensicherheit, da die Daten nicht zusätzlich auf einem entfernen Server liegen, sofern nicht zusätzliche Backups durchgeführt werden.
Zentrale Versionsverwaltung
Eine zentrale Versionsverwaltung ist hingegen häufig in produktiven Umgebungen zu finden. Subversion und CVS (Concurrent Versions System) sind beispielsweise Vertreter der zentralen Versionsverwaltung. Hauptmerkmal ist, dass das Repository lediglich auf einem zentralen Server liegt. „Repository“ ist ein englisches Wort für „Lager“, „Depot“ oder „Quelle“. Ein Repository ist somit ein Lager, in dem die Daten liegen. Autorisierte Nutzer eines Repositorys arbeiten dabei lokal mit einer Arbeitskopie der im Repository vorhandenen Dateien. Die Logik der Versionsverwaltung liegt dabei auf dem zentralen Server. Wenn man also auf eine andere Revision wechseln möchte oder sich die Revisionsänderungen anschauen möchte, werden stets die Daten vom Server heruntergeladen.
Verteilte Versionsverwaltung
Zu den verteilten Versionsverwaltungssystemen gehört nicht nur Git, sondern unter anderem auch bazaar oder Mercurial. Im Gegensatz zur zentralen Versionsverwaltung besitzt jeder Nutzer des Repositorys nicht nur eine Arbeitskopie, sondern das komplette Repository. Wenn also zwischen verschiedenen Revisionen gewechselt wird oder man sich die letzten Änderungen anschauen möchte, muss nur einmal das Repository geklont werden. Danach stehen alle Funktionalitäten der Versionsverwaltung offline zur Verfügung. Dadurch wird nicht nur unnötiger Netzwerktraffic vermieden, sondern auch die Geschwindigkeit wird, durch den fehlenden Netzwerk-Overhead, deutlich erhöht. Zusätzlich besitzen verteilte Versionsverwaltungssysteme eine höhere Datensicherheit, da die Daten des Repositorys in der Regel auf vielen Rechnern verteilt liegen. Dies ist somit quasi eine Kombination der beiden Konzepte der zentralen und lokalen Versionsverwaltung.
Geschichtliches
Lange Zeit nutzten die Entwickler des Linux-Kernels das proprietäre Versionsverwaltungssystem BitKeeper. Nach einer Lizenzänderung seitens der Herstellerfirma von BitKeeper konnte das Team um den Linux-Kernel, allen voran Linus Torvalds, BitKeeper nicht mehr kostenfrei verwenden, weswegen Linus Torvalds mit der Entwicklung von Git begann.
Da die Entwicklung im Jahr 2005 begann, gehört Git zu den jüngeren Versionsverwaltungssystemen. Für Linus Torvalds war es wichtig, dass das künftige Versionsverwaltungssystem drei spezielle Eigenschaften besitzt. Dies ist zum einen Arbeitsabläufe, die an BitKeeper angelehnt sind, Sicherheit gegen böswillige und unbeabsichtigte Verfälschung des Repositorys, sowie eine hohe Effizienz. Das Projekt Monotone, ebenfalls ein Versionsverwaltungssystem, wäre fast perfekt gewesen. Es fehlte lediglich die Effizienz. Mit Git erschuf Linus Torvalds dann doch eine eigene Versionsverwaltung, die nicht auf den Quellen von Monotone oder BitKeeper beruht.
Interessant ist auch die Namensnennung von Git. Git ist das englische Wort für „Blödmann“. Linus Torvalds selbst sagte spaßeshalber: „I’m an egoistical bastard, and I name all my projects after myself. First ‘Linux’, now ‘Git’.“ (Deutsch: „Ich bin ein egoistischer Mistkerl, und ich nenne alle meine Projekte nach mir selbst. Erst ‘Linux’ und nun ‘Git’.“) Natürlich gibt es auch praktische Gründe, das Projekt „git“ zu nennen. Zum einen enthält das Wort lediglich drei Buchstaben, was das Tippen auf der Tastatur erleichtert, zum anderen gab es kein gebräuchliches UNIX-Kommando, mit dem es kollidieren würde.
Arbeiten mit Git
Wie oben schon einmal kurz angerissen, ist ein Git ein verteiltes Versionsverwaltungsprogramm. Das ganze Repository mit all ihren Informationen liegt dabei nicht nur auf dem Server sondern auch auf dem lokalen Rechner. Dieser Fakt ist ein zentraler Punkt um mit Git sinnvoll arbeiten zu können und um das Konzept dahinter zu verstehen.
Ein Git-Repository besteht aus mehreren Bestandteilen. Allumfassend ist das Repository, welches diverse Branches besitzt. Branches wiederum bestehen aus mehreren Commits. Dieses Kapitel geht auf die Eigenschaften ein, aus denen ein Repository besteht und beantwortet einige Fragen.
Was ist ein Commit?
Kurz ausgedrückt stellt ein Commit in einem Repository eine Änderung dar. In einem Commit werden mehrere Informationen erfasst und gespeichert. Darunter fällt der Zeitpunkt des Commits, der Autor, eine Änderungsnotiz und die Änderung selbst. Die Änderung selbst kann groß und klein sein. Man kann etwa vollständig neue Dateien dem Repository hinzufügen oder auch nur eine kleine Sache in einer Datei ändern. Auch ein Löschen von Zeilen oder einer ganzen Datei sind eine Änderung und können in einem Commit erfasst werden. Neben den bereits genannten Punkten besitzt jeder Commit eine eindeutige Hash-Summe mit der sie kollisionsfrei referenziert werden kann.
Wichtig beim Arbeiten mit Git und vorallem beim kollaborativen Arbeiten ist, dass man sinnvolle Commits bildet. Auch wenn sich dies auf dem ersten Blick einfach liest, kann man da doch einiges falsch beziehungsweise ungünstig machen. Es gibt kein allgemeingültiges Rezept für gute Commits, auch unterscheiden sich in diesem Punkt die Ansichtsweisen von Git-Nutzern.
Insbesondere beim Entwickeln von Software ist es sinnvoll, wenn man jeden Commit thematisch abgrenzt. Der Commit selbst sollte durch die Commit-Nachricht, also der Änderungsnotiz, angemessen beschrieben werden. Wenn man zum Beispiel in einer Software ein paar Icons auswechselt, ist es ratsam hierfür einen Commit zu erstellen. Was man in dem Zuge nicht machen sollte, ist etwa Änderungen am Code und an Grafiken innerhalb eines Commits zu vermischen. Passende Commit-Nachrichten sind ebenfalls angebracht, da man hinterher sehr gut und auch einfacher überblicken kann, warum man eine Änderung gemacht hat und was diese enthält. Commit-Nachrichten wie „Aktueller Stand“ sollte man daher möglichst vermeiden.
Was ist ein Branch?
Ein wichtiges Element von Git und auch anderen Versionsverwaltungsprogrammen ist das Arbeiten mit Branches. Das Wort „Branch“ lässt sich in diesem Fall am Besten mit „Zweig“ übersetzen. Es ist möglich, den aktuellen Entwicklungsstand abzuzweigen und daran weiter zu entwickeln. Konkret bedeutet dies, dass quasi eine Kopie vom aktuellen Arbeitsstand erzeugt wird und man dort weitere Commits tätigen kann, ohne eine andere Entwicklungslinie zu berühren. Die Nutzung von Branches ist eine zentrale Eigenschaft von Git, insbesondere in der Software-Entwicklung. In der Praxis sieht das dann meistens so aus, dass einzelne Features in einzelnen Branches entwickelt werden und dann nach und nach in den Haupt-Entwicklungszweig zusammengeführt werden. Häufig ist es allerdings so, dass man auch noch ältere Versionen pflegt, die etwa noch mit Sicherheitsaktualisierungen versorgt werden müssen. So kann man recht einfach von einem Entwicklungszweig auf einen anderen Branch wechseln und dort noch schnell einen Fehler korrigieren. Anschließend kann man wieder zurück wechseln und an seinem Feature weiterarbeiten. Das ganze Vorgehen hilft den Programmierern zwischen verschiedenen Versionen und Entwicklungslinien zu springen, ohne großen Aufwand betreiben zu müssen.
Was heißt Mergen?
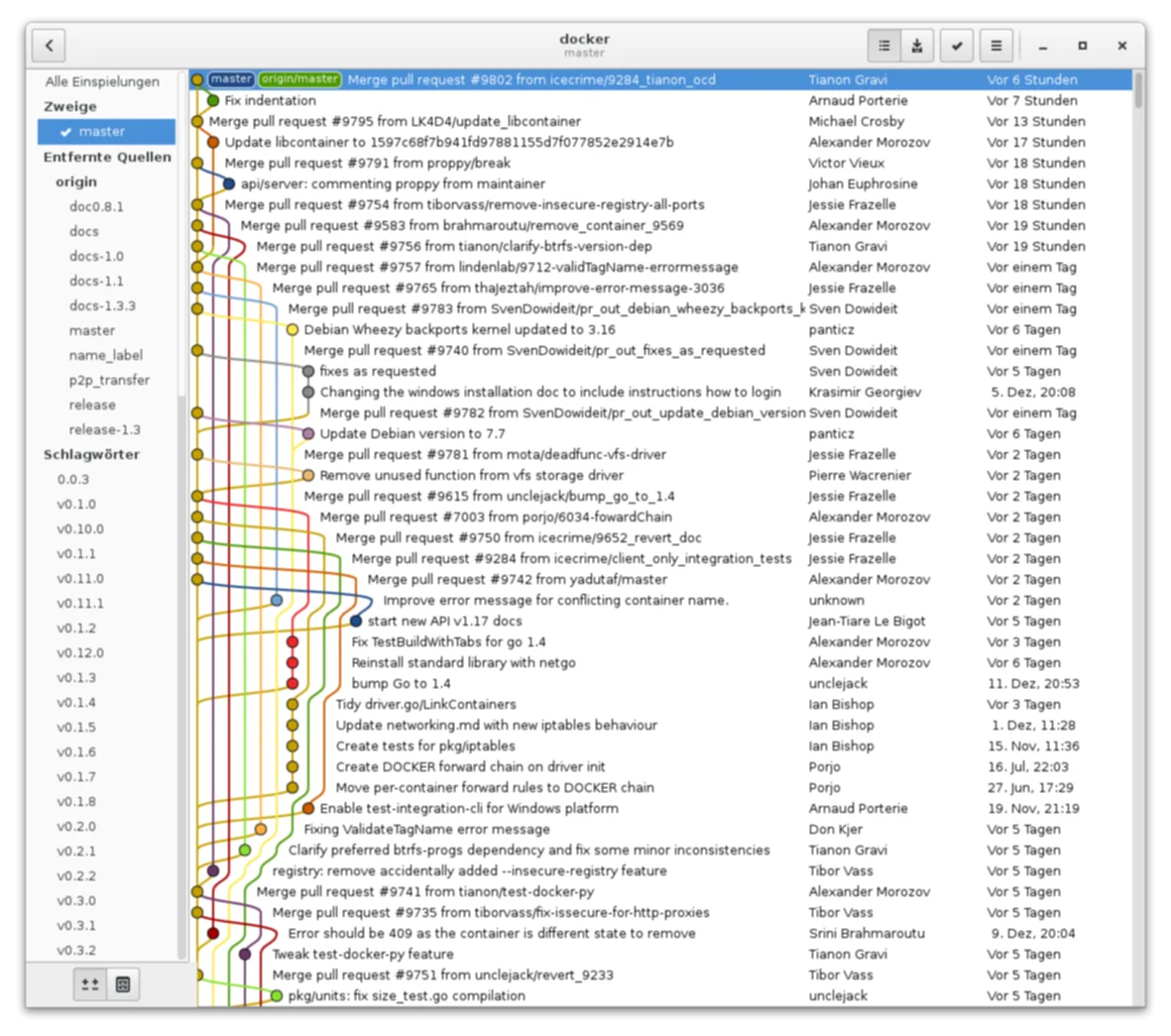
Wie bereits erwähnt, werden häufig einzelne Features in Software-Projekten in einzelnen Branches entwickelt. Dies hat den Vorteil, dass man sich auf die Arbeit an diesem einzelnen Feature konzentrieren kann und nicht von anderen Änderungen von anderen Features betroffen ist. Wenn ein Entwicklung allerdings abgeschlossen ist, will man diese Änderungen natürlich wieder in den Hauptentwicklungs-Branch integrieren. In größeren Projekten tut sich auf diesen Branch auch einiges, so dass diese beiden Branches vereinigt werden müssen. Den Prozess des Vereinigens nennt man „mergen“. Mit einem simplen Befehl können so zwei Entwicklungslinien miteinander verschmolzen werden. Dies funktioniert allerdings nicht immer einwandfrei und problemlos. So kann es nämlich vorkommen, dass in beiden Branches Änderungen an der selben Zeile durchgeführt worden sind. Hierbei kann es dann zu Merge-Konflikten kommen, die dann vom jeweiligen Entwickler händisch gelöst werden müssen.
Für Entwickler bieten Branches und das Mergen eine einfache und schnelle Möglichkeit, einige Dinge zu testen. So kann man fix einen Branch anlegen, wenn man eine bestimmte Änderung testen möchte, die man nicht in seinem Entwicklungs-Branch haben möchte. Falls man mit der Änderung zufrieden ist, kann man sich dann auch ganz einfach mergen oder eben auch verwerfen. So stört man nicht den Entwicklungsfluss im Hauptentwicklungs-Branch sondern kann auch kurze einfache Tests durchführen ohne das es andere Entwickler im Team stört.
Was sind Remote-Repositorys?
Eine weitere große Stärke von Git ist, dass man ein Repository auf vielen verschiedenen Rechnern verteilen kann. Ein vollständiges Git-Repository kann an vielen verschiedenen Orten liegen. Wichtig für das Verständnis ist, dass in der Theorie jedes Git-Repository mit jedem gleichgestellt ist. In der Praxis sieht das allerdings etwas anders aus, da meistens bei Projekten mit einem zentralen Server gearbeitet wird.
Entfernt liegende Repositories nennt man Remote-Repositorys. Es bietet sich grundsätzlich immer an, mit Remote-Repositorys zu arbeiten. Ein Projekt, dessen Git-Repository nur auf einem lokalen Rechner liegt, ist kaum vor Ausfällen gesichert. Sie sind insbesondere deshalb nützlich, da man damit einfach kollaborativ arbeiten kann.
Remote-Repositorys können an verschiedenen adressierbaren Stellen lagern. Darunter fällt auch der lokale Rechner, was aber, wie oben schon erwähnt, nicht sonderlich praktikabel ist. Es gibt verschiedene Dienste um git auf dem Server zu betreiben. Dies kann man entweder selbst hosten, oder aber externe Dienste wie GitHub nutzen.
Welche Schichten gibt es beim Einsatz von Git?
Beim Einsatz von Git ist es wichtig zu verstehen, welche verschiedenen Schichten es gibt. Die Schichten sind nicht fest an ein einzelnes Repository gebunden sondern gehen darüber hinaus auf den ganzen Entwicklungsprozess mitsamt Remote-Repositorys ein. Insgesamt gibt es beim Arbeiten mit Git fünf Schichten die man kennen muss, die im folgenden erläutert werden.
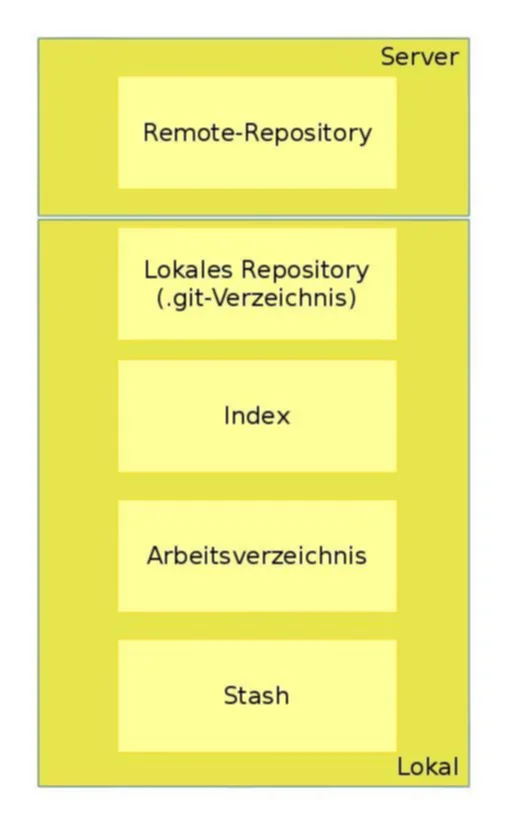
Remote-Repository
Remote-Repositorys wurden schon in diesem Artikel erläutert. An jedem lokalen Repository kann man mehrere Remote-Repositorys konfigurieren, wo man seine Änderungen abholen und hinschieben kann. Natürlich unter der Voraussetzung, dass man die nötigen Berechtigungen für das entsprechende Remote-Repository besitzt.
Lokales Repository
Das lokale Repository erklärt sich schon fast selbst. Das ist der Teil des Repositorys, welches auf dem lokalen Rechner befindet. Dies umfasst insbesondere ‘’nicht’’ die Dateien des Repositorys, mit denen man arbeitet. Das lokale Repository ist als ‘’.git’’-Unterordner im Projekt enthalten. Darin sind alle Informationen des Repositorys enthalten, wie etwa die Commits und die Branches.
Index
Der Index wird häufig auch Staging-Bereich genannt. Im Index landen alle Dateien, die man für ein Commit vormerkt. Dieser Bereich ist daher in der Regel nicht persistent, da man nur solange den Index mit Dateien beziehungsweise Änderungen an Dateien füllt, bis man einen Commit getätigt hat.
Workspace
Der Workspace, auch Arbeitsbereich genannt, ist der Teil des Repositorys, welches die Dateien enthält, mit denen man arbeitet. Das heißt, wenn man ein Repository von einem Remote-Repository geklont hat, also eine Kopie heruntergeladen hat, dann umfasst der Workspace bei einem Software-Projekt den Quellcode. Im Unterschied zum lokalen Repository, enthält der Workspace keinerlei Informationen über andere Branches. Man spricht beim Workspace auch von „ausgescheckten“ Dateien, da der Workspace eine Revision des Repositorys darstellt.
Stash
Stash kann man gut mit „Lager“ oder „Geheimversteck“ übersetzen. Im Kontext von Git kann man geänderte Dateien, die man noch nicht committen möchte, kurzfristig in den Stash legen. Dies ist insbesondere dann sinnvoll, wenn zwar an einigen Dateien gearbeitet hat, aber man noch kurzfristig eine Änderung auf einem anderen Branch machen möchte. Die geänderten Dateien lassen sich so schnell in den Stash verschieben und bei Bedarf wieder herausholen.
Ist Git gleich GitHub?
Git-Repositorys möchte man idealerweise auf einem Server lagern, den man über das öffentliche Internet erreichen kann. Es gibt mehrere Möglichkeiten Git auf dem Server zu installieren. Wenn man hingegen nicht ein eigenen Git-Server einrichten möchte, kann man auch externe Dienste verwenden. Der bekannteste Dienst ist wohl GitHub. Einige Personen setzen Git und GitHub gleich, was allerdings so nicht stimmt. Weder ist Git selbst GitHub, noch ist GitHub Git! Grob gesagt, ist GitHub eine Erweiterung von Git um kollaborativ oder auch alleine an einem Projekt zu arbeiten. Viele Open-Source-Projekte hosten ihre Git-Repositorys auf GitHub, darunter GitHub, PHP und auch die ubuntuusers.de-Software Inyoka. GitHub vereinfacht den Austausch zwischen den Teilnehmern an einem Projekt, da man dort nicht nur Fehler an einem Projekt melden kann, sondern theoretisch auch direkt selbst korrigieren kann.
GitHub arbeitet stark mit sogenannten „Forks“. Fork ist der englische Begriff für „Gabel“. Ein Fork ist allerdings in diesem Kontext eine Abspaltung eines Projekts. Bei einigen Projekten sieht man des öfteren Slogans wie „Fork us on GitHub“. Wenn man einen GitHub-Account besitzt und dann ein Projekt forkt, dann legt GitHub im eigenen Benutzer-Konto ein Klon des Repositorys an, wo man selbst Schreibrechte besitzt. So kann man die gewünschten Änderungen selbst durchführen, diese commiten und anschließend das Repository wieder auf GitHub pushen. Die Änderungen sind dann zwar im eigenen Fork online, sollten aber dem Hauptprojekt zurückgeführt werden. Dafür bietet GitHub die „Pull-Request“-Funktion an. Ein Pull-Request ist prinzipiell nichts weiter als eine Bitte die eigenen durchgeführten Änderungen in das Haupt-Repository zu „pullen“, also einzufügen. Nach Prüfung kann man dann per Knopfdruck im Browser die Änderungen in das Haupt-Repository übernommen werden.
Die erläuterten Funktionen beschränken sich auf die gängigsten Funktionen von GitHub. Es gibt noch einige weitere Funktionen die allerdings den Rahmen des Artikels sprengen würden. GitHub wird häufig auch als „Social-Coding“ Plattform bezeichnet, da man nicht nur einfach zu anderen Entwicklern in Kontakt treten kann, sondern auch deren Entwicklungen verfolgen kann.
GitHub ist nicht die einzige Plattform, die solche Funktionen abbildet. Es gibt auch weitere Plattformen wie etwa BitBucket. Am verbreitetsten ist jedoch GitHub. Für die Entwicklung von Ubuntu wird hauptsächlich Launchpad verwendet, welches man mit GitHub vergleichen kann. Allerdings nutzt Launchpad nicht Git, sondern Bazaar. Nachteilig von GitHub ist allerdings, dass die Software selbst nicht Open Source ist und jedes einzelne Repository mit einem kostenlosen Account öffentlich ist. Für private, nicht öffentliche Repositorys muss man dort zahlen.
Fazit
Der Einsatz von Git eignet sich zwar besonders für Software-Entwickler, doch auch für Autoren oder Grafiker kann sich ein Einsatz von Git lohnen, um zum einen eine Versionshistorie zu haben und zum anderen auch gut mit anderen kollaborieren kann.