Im letzten Teil ging es um das Rebasen und das Einrichten und Nutzen von Remote-Repositorys. In diesem Teil wird es rein um GitHub und dessen Workflow gehen. Darunter fällt unter anderem das Erstellen eines Repositorys und wie man sich an Open-Source-Projekten auf GitHub beteiligen kann.
Dieses Tutorium besteht aus vier Teilen. Wem das Tutorium gefällt und mehr über Git lernen möchte, der kann sich das Buch „Versionsverwaltung mit Git“ für 29,99€ bestellen. In diesem Buch, was ich geschrieben habe, werden die Themen rund um Git noch deutlich ausführlicher behandelt.
Was ist GitHub?
Im dritten Teil dieses Tutoriums wurde zwar erläutert wie man mit Remote-Repositorys arbeitet, allerdings fehlte bislang eine sinnvolle Möglichkeit um Repositorys auf entfernt liegenden Servern zu lagern, die man über das öffentliche Internet erreichen kann. Eines der Dienste um dies zu erledigen ist GitHub.
GitHub besitzt sehr viele Funktionen die sich um das kollaborative Arbeiten an Projekten mit Git drehen. Darüber hinaus besitzt GitHub zwar noch einige weitere Dienste, dieser Teil des Tutorium dreht sich allerdings mehr um die grundsätzlichen Funktionen, die Git betreffen.
Hinweis: Da GitHub stetig weiterentwickelt wird, ändert sich auch die Web-Oberfläche. Die in diesem Artikel enthaltenen Screenshots könnten bereits nach wenigen Monaten veraltet sein.
Repository anlegen
Bei GitHub können Git-Repositorys angelegt werden. Bevor man sein erstes Repository anlegen kann, muss man sich zunächst registrieren. Der Funktionsumfang mit einem Standardkonto ist auf öffentliche Git-Repositorys beschränkt, das heißt vor allem, dass alle Dateien aus den Repositorys öffentlich und somit für jeden lesbar sind. Gegen Bezahlung kann man auch private Repositorys anlegen.
Nach der Registrierung und dem Einloggen findet man in der oberen Leiste in GitHub diverse Bedienelemente, darunter auch ein Knopf um ein neues Repository bzw. eine neue Organisation anzulegen. Eine Organisation ist an dieser Stelle noch nicht so wichtig, kurz gesagt, kann man Organisationen anlegen, damit eine Gruppe an Entwicklern sich die Rechte an Repositorys teilen können. Wenn man hingegen einen Account als normalen Nutzer besitzt, sind die Rechte standardmäßig auf die eigenen Repositorys für sich alleine beschränkt.
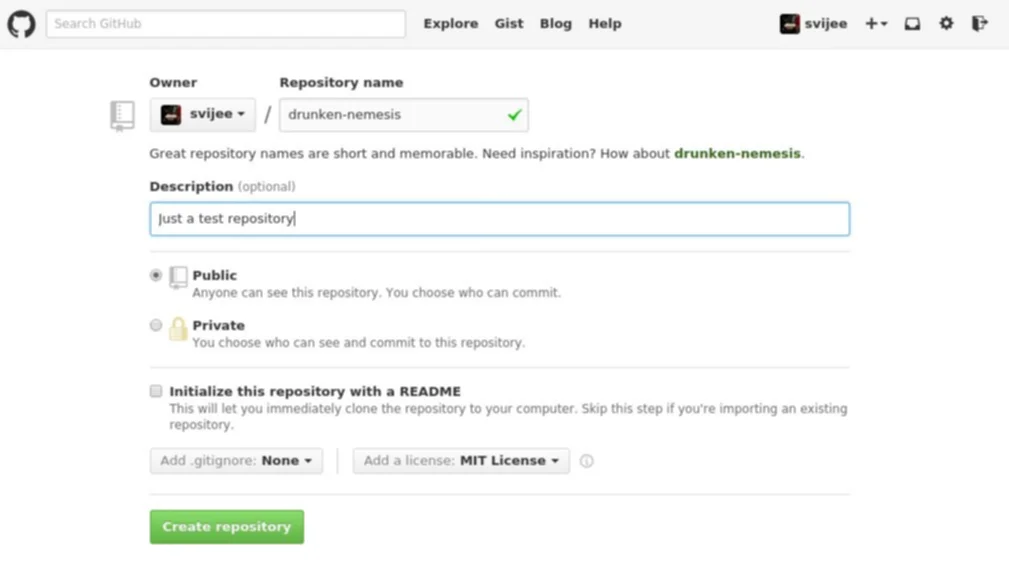
Wenn man nun ein Repository anlegen möchte, muss man dem Repository zunächst einen Namen vergeben. Optional ist hingegen eine kurze Beschreibung. Als zusätzliche Möglichkeit, kann man dem Repository direkt eine README-Datei hinzufügen lassen, ebenso wie eine “.gitignore”-Datei sowie eine Datei mit den Lizenz-Bestimmungen des Projektes im Repository.
Die “README”-Datei ist dafür da, um Informationen über das Projekt bzw. das Repository auf der Startseite des Repositorys darzustellen. GitHub stellt dies automatisch dar.
In diesem Tutorium wurde bislang noch nicht die Datei “.gitignore” behandelt. Innerhalb jedem Repositorys kann eine solche Datei anlegt werden. Alles was man dort einträgt, wird von Git schlicht ignoriert und somit nicht weiter beobachtet. Wenn man etwa an LaTeX-Dokumenten arbeitet, hat man bei jedem Kompilieren der TeX-Datei einige Dateien, die nicht direkt für das Projekt selbst relevant sind und somit auch eine Versionierung nicht notwendig ist. Diese Dateien kann man in der Datei “.gitignore” eintragen und Git zeigt diese Dateien in keinen der Befehle an. GitHub macht das Anlegen der Datei noch ein wenig komfortabler, da es sehr viele vordefinierte gitignore-Dateien anbietet, etwa für Java-, Android- oder TeX-Projekte.
Weiterhin kann man beim Anlegen eines Repositorys über GitHub eine Lizenz-Datei anlegen lassen. Dies ist wichtig, damit auch andere Leute von dem Inhalt des Repositorys profitieren können.
Wenn man nun einen Namen, eine Beschreibung sowie eine Lizenz-Datei ausgewählt hat und anschließend das Repository erzeugt, dann besitzt das Repository zu Beginn genau einem Commit mit der Commit-Message „Initial Commit“.
SSH-Key anlegen und hinzufügen
Bevor man das neu angelegte Repository klonen kann, muss man dem GitHub-Account noch einen SSH-Key hinzufügen. Sofern man auf dem lokalen Rechner noch kein SSH-Key erzeugt hat, muss zunächst ein Key anlegt werden.
Falls man nicht weiß, ob man schon mindestens einen SSH-Key besitzt, kann man den Inhalt vom Ordner “~/.ssh” überprüfen. Ein SSH-Key setzt sich aus zwei Dateien zusammen. Dies ist zum einen der private und zum anderen der öffentliche Schlüssel. Beispielsweise ist die Datei “id_rsa” der private Schlüssel, während “id_rsa.pub” öffentlicher Schlüsselteil ist.
Sofern man noch keinen SSH-Key angelegt hat, kann man das mit dem folgenden Befehl erledigen:
$ ssh-keygen -t rsa -C "mail@svij.org"
Generating public/private rsa key pair.
Enter file in which to save the key (/home/sujee/.ssh/id_rsa): /home/sujee/.ssh/id_github
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/sujee/.ssh/id_github.
Your public key has been saved in /home/sujee/.ssh/id_github.pub.
The key fingerprint is:
SHA256:LFM8YkUe+ACh4+mH0GXZ4xAlWXT3zpHDEKdg/r9jBHI mail@svij.org
The key's randomart image is:
+---[RSA 2048]----+
| =B+oB +.. |
| ..=oB + * . |
| o = =o. . * |
| o = + =ooEo o |
|. + + So..o |
| o . o .. |
| o . .. |
| . o. |
| ... |
+----[SHA256]-----+
Beim Ausführen des gelisteten Befehls werden interaktiv einige Fragen gestellt, die beantwortet werden sollten. Darunter den exakten Speicherort des Schlüssels, sowie ein Passwort. Man kann zwar auch einen Schlüssel ohne Passwort generieren, dies ist allerdings nicht empfehlenswert, da man sonst vollständigen Zugriff auf die Repositorys erhält, falls der private Schlüssel in falsche Hände gerät.
Nachdem nun das Schlüsselpaar generiert worden ist, muss nun der öffentliche Schlüssel in GitHub eintragen werden. Der öffentliche Schlüssel liegt in diesem Beispiel in “~/.ssh/id_github.pub”. In den GitHub-SSH-Einstellungen muss dann der Inhalt dieser Datei eingefügt werden.
Repository klonen
An dieser Stelle kann man das Repository erstmals klonen. Dazu braucht man die URL, um es über SSH zu klonen. Dies findet man entweder auf der GitHub-Repository-Seite oder man setzt es sich selbst zusammen, da es immer dem gleichen Schema folgt. In meinem Beispiel heißt das Repository „drunken-nemesis“ im Nutzer-Konto „svijee“. Das Repository findet sich daher unter https://github.com/svijee/drunken-nemesis. Unter der rechten Seitenleiste auf GitHub findet sich die URL zum Klonen via SSH, HTTPS oder Subversion. Relevant ist in der Regel nur das Klonen via SSH.
$ git clone git@github.com:svijee/drunken-nemesis.git
Klone nach 'drunken-nemesis'...
Enter passphrase for key '/home/sujee/.ssh/id_github':
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Empfange Objekte: 100% (3/3), Fertig.
Prüfe Konnektivität... Fertig.
Wenn man das Repository direkt klont, konfiguriert Git automatisch das geklonte Repository als das „origin“ Remote-Repository. Dies kann man nachvollziehen, wenn man in das Verzeichnis wechselt und dort die Remote-Repositorys auflistet.
$ cd drunken-nemesis
$ git remote -v
origin git@github.com:svijee/drunken-nemesis.git (fetch)
origin git@github.com:svijee/drunken-nemesis.git (push)
Anschließend kann man alle gewünschten Funktionen von Git nutzen, wie das Erstellen von Branches und Commits. Diese können dann anschließend gepusht werden, um die Änderungen über GitHub zur Verfügung zustellen. Die Änderungen lassen sich auch auf der Webseite von GitHub selbst ansehen, sodass man Repositorys nicht zwangsläufig klonen muss. Unter github.com/svijee/drunken-nemesis/commits/master finden sich etwa alle Commits die auf dem Branch “master” getätigt wurden. Ebenfalls kann man dort zwischen den Branches wechseln.
GitHub-Workflow
Das Besondere an GitHub ist, dass es nicht nur eine einfache Möglichkeit bietet eigene Git-Repositorys zu hosten, sondern auch, dass man mit wenigen Schritten Änderungen an Repositorys von anderen Personen oder Organisationen vorschlagen kann, die dann übernommen werden können.
Jedes GitHub-Repository lässt sich im Browser forken. Bei einem Fork spricht man von einer Abspaltung. Hin und wieder hört man bei größeren Open-Source-Projekten, das ein Fork entstanden ist. So ist die Büro-Suite LibreOffice ein Fork von OpenOffice.org, wo allerdings nicht die Änderungen zu OpenOffice.org zurückgeflossen sind. Bei GitHub hat ein Fork in der Regel eine etwas andere Bedeutung. In der Regel liegen die Zugriffsberechtigungen an einem Repository allein bei dem Besitzer des Repositorys. Über GitHub kann man nun Änderungen an einem Repository vorschlagen, dazu muss man den Fork-Button im Browser drücken. Dann wird eine Kopie (der Fork) des Repositorys erzeugt und im eigenen Account abgelegt. Dort besitzt man anschließend alle nötigen Schreibrechte. Wenn man also an dem Repository svijee/drunken-nemesis Änderungen vorschlagen möchte, erstellt GitHub nach dem Drücken des Fork-Buttons eine Kopie des Repositorys unter $DEINNAME/drunken-nemesis. GitHub zeigt selbst direkt auch an, dass es sich um einen Fork des Haupt-Repositorys handelt.
An dem Fork kann man nun wie gewünscht auf einem Branch die gewünschten Änderungen in Form von Commits durchführen. In der Regel bietet es sich an, dafür einen extra Branch anzulegen in dem man die Commits hinzufügt. Fehlen darf dafür natürlich kein Beispiel:
$ git clone git@github.com:$DEINUSERNAME/drunken-nemesis.git
$ cd drunken-nemesis
Anschließend kann man etwa eine Datei namens “README” mit beliebigen Inhalt hinzufügen, die anschließend commited werden kann.
$ git add README
$ git commit -m "README Datei hinzugefügt."
Zur Wiederholung: Wichtig ist an diesem Punkt, dass man nicht vergisst das Repository zu GitHub zu pushen. Da Git bekanntlich ein verteiltes Versionsverwaltungssystem ist, sind die Änderungen bis zu diesem Punkt nur lokal verfügbar. Daher muss man noch “git push” ausführen, um die Änderungen zu dem Remote-Repository auf GitHub zu übertragen.
Anschließend kann man über GitHub den sogenannten Pull-Request erstellen, in dem man die Änderungen die man gemacht hat, dem Haupt-Repository zur Übernahme vorschlägt. Bei jedem Repository, wo die Pull-Request-Funktion nicht abgeschaltet wurde, findet sich auf der Repository-Seite der Menüpunkt „Pull Requests“ auf der sich vorhandene, offene Pull-Requests befinden und auch neue angelegt werden können. Beim Anlegen müssen dann beide Branches, jeweils aus dem Quell- und Ziel-Repository, ausgewählt werden, die zunächst verglichen werden können. Sofern alle benötigten Änderungen in dem Pull-Request enthalten sind, kann der Request angelegt werden. Die Mitarbeiter an dem Haupt-Repository, an dem der Pull-Request gestellt wurde, können diesen Kommentieren oder direkt annehmen.
Arbeiten mit zwei Remote-Repositorys
Wenn man regelmäßig an einem Projekt über GitHub beiträgt, bietet sich eine lokale Konfiguration an, die das Arbeiten mit zwei Remote-Repositorys erleichtert. Dadurch, dass man letztendlich mit zwei Repositorys arbeitet, müssen beide korrekt verwaltet werden. So gibt es einmal das eigene Repository, in dem man Schreibrechte besitzt und das Repository des Projektes, wohin die Pull-Requests und auch anderen Änderungen des Projektes fließen. Man sollte daher immer beachten, dass man sein eigenes Repository auf dem eigenen Stand hält.
Wenn die oben aufgeführten Befehle ausgeführt hat, ist der eigene Fork als Remote-Repository “origin” konfiguriert. Dies sollte man genau so belassen, da man alle Branches in das eigene Repository pusht. Jetzt sollte man das Repository des Projektes ebenfalls als Remote-Repository hinzufügen, hier bietet es sich an, es “upstream” zu nennen, da es sich schließlich um das Upstream-Projekt handelt.
$ git remote add upstream git@github.com:svijee/drunken-nemesis.git
Jetzt ist zwar das Repository konfiguriert, allerdings sind die Änderungen noch nicht heruntergeladen. Dies kann man mit einem der beiden aufgeführten Befehle durchführen.
$ git remote update
$ git fetch upstream
Während der erste Befehl alle Remote-Repositorys herunterlädt, lädt letzterer Befehl nur das Remote “upstream” herunter. In der Regel ist es nun so, dass sich auf dem Upstream-Repository einiges tut, diese Änderungen müssten dann regelmäßig in das eigene Repository übernommen werden. Dazu sollte man regelmäßig “git remote update” ausführen und anschließend den Branch aus dem Remote-Repository in den Branch des eigenen Repositorys mergen. In diesem Beispiel, ist es der Branch “master” den man aktualisieren möchte.
$ git merge upstream/master
Sofern keine Änderungen auf dem Branch “master” im eigenen Repository sind, sollte der Merge problemlos funktionieren. Änderungen, die man dem Haupt-Repository beifügen will, sollte man daher immer in einem neuen Branch anlegen, um Merge-Konflikte zu vermeiden.
Häufig passiert es aber auch, dass man Pull-Requests anlegt, die zu einem späteren Zeitpunkt nicht mehr automatisch ohen Konflikte gemergt werden können. Als Einreicher von Pull-Requests sollte man also immer darauf achten, dass der Pull-Request ohne Konflikte gemergt werden kann. Da dies nicht immer möglich ist, müssen gegebenfalls Commits aus dem Entwicklungs-Branch des Haupt-Repositorys übernommen werden. Diese kann man entweder mit dem “git merge” Befehl mergen, schöner ist es allerdings, wenn man ein Rebase durchführt, der im dritten Teil dieses Tutoriums erläutert wurde.
Weitere Funktionen von GitHub
GitHub bietet nicht nur das Hosten von Repositorys an. Die Funktionen sind mittlerweile vielfältig und decken so gut wie alle Wünsche ab, die man für ein Software-Projekt haben kann. Darunter ein Ticket-System („Issues“) und ein Wiki. Beides ist direkt über das Repository zu erreichen. Daneben kann man auch statische Webseiten mit GitHub Pages hosten oder Gists als Lager für einzelne Dateien anlegen.
Alternativen
GitHub ist nicht die einzige Plattform, welche das Hosten von Repositorys mit sinnvollen Features erweitert um einfach und kollaborativ an Projekten zu arbeiten. So hat GitHub auch Nachteile, etwa steht es selbst nicht unter eine Open Source Lizenz und das Hosten von privaten, nicht öffentlichen Repositorys kostet Geld.
Als Alternative seien Gitlab und Bitbucket genannt, bei denen man auch private Repositorys mit einigen Begrenzungen kostenlos hosten kann. Gitlab kann man aber auch selbst auf eigenen Servern hosten, sodass man etwa für den Firmen-internen Gebrauch von Closed Source Software den Quellcode nicht auf fremde Server hochladen muss.