In den letzten Wochen habe ich mein verteiltes Backup-Konzept umgesetzt, das ich in diesen Blogpost beschreiben werde. Ziel war es alle wichtigen Daten mehrfach und verteilt gesichert zu haben. Und das heißt nicht nur auf verschiedenen Rechnern im selben Haus, sondern auch “in der Cloud”. Dann natürlich verschlüsselt.
Prinzipiell folge ich den 8 goldenen Backup-Regeln von Stefan Betz. Insbesondere Regel 2 und 3 sind wichtig: Man hat mindestens zwei Backups der Daten und nicht gesicherte Daten sind nicht wichtig.
Insgesamt habe ich drei verschiedene Rechner die Daten haben: Ein Desktop-Rechner, ein Laptop und ein Homeserver. Der Homeserver läuft immer durch, während der Laptop und der PC nicht durchgängig laufen. Sowohl der Homeserver als auch der PC sollten alle Daten besitzen, während der Laptop die Daten auch vom Homeserver beziehen kann. Demnach dient der Homeserver auch als Datenserver per NFS. Dies ist wichtig für das Planen des Backups.
Vor dem Erstellen der initialen Backups ist es erst einmal wichtig alle Daten aufzuräumen. Ich habe etwa etliche Daten gelöscht, die ich eh nicht mehr brauchte und auch doppelte Daten gelöscht, die sich in verschiedenen Ordnern versteckt haben. Mein Home-Directory existiert auch schon seit über fünf Jahren, da versteckt sich übrigens auch sehr viel alter Kram in versteckten Ordnern, die ebenfalls einige Gigabyte an Platz belegen können. Nach dem Aufräumen gab es dann für mich zwei Arten von Daten: Daten die wichtig sind und Daten die nicht wichtig sind. Nicht wichtige Daten sind Daten, die ich mir andersweitig wieder besorgen kann. Also sowas wie ISO-Images von Linux-Distributionen oder auch Dinge wie Filme. Diese müssen nicht gesichert werden. Anders sieht es aber mit Daten aus die wirklich fast nur ich selbst hatte: Jahr(zehnt)e alte digitale Fotos, Urlaubsvideos, Dokumente (etwa Zeugnisse) usw. Die wichtigen Daten beschränken sich bei mir auf gerade einmal 300 GB. Davon geht das meiste auf die Fotos und Videos drauf. Da hängen schließlich sehr viele Erinnerungen dran, die ich nicht verlieren will.
Insgesamt ergaben sich einige Anforderungen die mein Backup-Konzept umfassen sollte:
- Verteilt (im und außerhalb des Hauses)
- Verschlüsselt (auf Dateisystemebene und/oder pro Datei)
- Versioniert (über Monate/Jahre)
- automatisiert
- muss mit Linux tools laufen (Windows ist nicht im Einsatz)
Als Backup Tool griff ich zum Kommandozeilentool BorgBackup. Das Tool ist nicht nur schnell, sondern kann auch einfach Daten verschlüsseln und komprimieren. Versionierung wird auch unterstützt und auch das nachträgliche Löschen von einzelnen Versionsständen ist möglich. Es gibt zwar viele verschiedene Backup-Tools, aber Borg bot für mich recht schnell ein gutes Feature-Set, was sich mit wenigen und einfach verständlichen Kommandos bedienen lässt. Auch die Doku ist modern und aufgeräumt, sodass man da vieles schnell findet. Ich wollte nämlich definitiv nicht ein Backup-Tool verwenden, wo ich nicht ganz verstehe wie das funktioniert oder was zu kompliziert ist. Denn sonst hat man schnell das Problem, dass man beim Einspielen des Backups vor Problemen steht. Im Wiki von ubuntuusers.de gibt es übrigens seit kurzem auch eine Dokumentation auf Deutsch.
Beim Erstellen des initialen Backups mit Borg habe ich die Verschlüsselung mittels eines “keyfiles” gewählt. Auch mit der Kompression habe ich etwas vorher getestet und mich letztendlich für zlib,9 entschieden, was nicht allzu viel Zeit in Anspruch nahm und auch eine angenehme Kompression bot. Stefan hat sich die verschiedenen Kompressionsstufen näher angeschaut und festgestellt, dass LZ4 deutlich schneller die Kompression durchführt und nur wenig mehr Platz auf der Festplatte verbraucht. Näheres findet sich in seinem Blogpost. Ich verbleibe trotzdem bei zlib, da sich die initiale Kompression schon lange durch ist und die inkrementellen Backups sowieso nur wenige Minuten dauert, da sich nicht sehr viele Daten verändern.
Borg wird von den beiden Clients – dem PC und dem Laptop – ausgeführt und speichert diese direkt auf dem Homeserver, wo ebenfalls Borg läuft. Vom PC läuft zusätzlich ein regelmäßiger rsync auf den Homeserver der nackten Daten, damit dieser weiterhin als Fileserver dienen kann. Die Daten liegen so gesehen dann doppelt auf dem Homeserver: Einmal ohne irgendwelche Kompression und Verschlüsselung und einmal in dem Borg Archiv. Der komplette Aufbau sieht wie folgt aus:
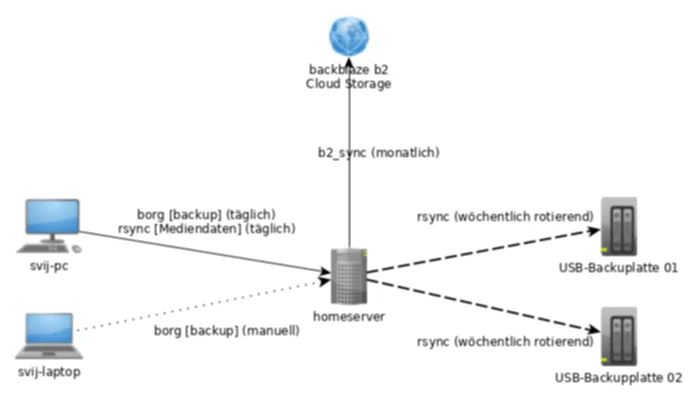
Mein Rechner führt per eingerichteten systemd-timer 10 Minuten nach dem ersten Boot an einem Tag das Skript aus, was rsync aufruft und ein neues inkrementelles Borg Backup durchführt. Da sich meist nicht so viel ändert, geht das in der Regel recht zügig. Da der Laptop meist außerhalb des Heimnetzes aktiv ist, ist dort kein systemd-Timer eingerichtet, dort mache ich es in der Regel händisch, dort liegen aber zumeist auch selten wichtige Daten drin, da notwendigen Daten sowieso über Git-Repositorys und Nextcloud synchronisiert werden.
Im wöchentlichen rotierenden Rhythmus werden zusätzlich die USB Backup-Platten befüllt. Die Platten selbst sind nicht verschlüsselt, da das Borg-Archiv schon verschlüsselt ist. Damit sind die In-House Backups schon abgehandelt. So liegen die Daten auf vier verschiedenen Datenträgern verteilt: auf dem PC, dem Homeserver und den beiden Backup-Platten. Im Falle eines Hardware-Defekts an einem Gerät ließe sich das Backup relativ einfach wieder einspielen und im minimalen Fall sind Daten von einem Tag verloren.
Was trotzdem noch fehlt ist ein Offsite-Backup. Es gibt verschiedene Cloud-Anbieter die Backup-Systeme anbieten. Zu den bekannteren zählt wohl Amazon Glacier. Dies wollte ich zu Beginn auch verwenden, da die Kosten von 0,007 USD pro GB und Monat nicht hoch sind. Allerdings ist AWS von der Benutzerführung schrecklich und auch die Kosten sind schwierig zu berechnen, wenn man Daten wiederherstellen muss, das auch wieder Geld kostet. Ein kurzer Test meinerseits brachte mir die Erkenntnis, dass ich das aus komplizierten Preis- und Nutzungsstruktur nicht verwenden wollte. Eine Alternative war Google Archival Cloud Storage. Dort kostet die Archivierung im “Coldline” ebenfalls 0,007 USD pro GB und Monat. Da gab es nur ein völlig anderes Problem: Google bietet die Cloud Dienste nur für Geschäftskunden in Deutschland an - Privatkunden bleiben somit komplett außen vor. Das ist in anderen Ländern nicht so, da man in den USA etwa auch als Privatperson sich ein Google Cloud Platform Konto klicken darf. Eine weitere Alternative war dann der eher kleine Anbieter Backblaze aus den USA. Dort kostet das B2 Cloud Storage sogar nur 0,005 USD pro GB und Monat. Ein Download der Daten kostet dort ebenfalls ungefähr so viel. Im Gegensatz zu Amazon Glacier kriegt man die Daten auch recht schnell wieder heruntergeladen, da man hier nicht 3-4h warten muss, bis das Backup zum Download wieder bereitsteht. Backblaze bietet auch ein Command Line Tool an, was Open Source ist. Womit die Daten hochgeladen werden können. Dies ist ein Python Pip Paket, was sich recht einfach in einem Virtualenv installieren und nutzen lässt.
Wichtig bei einem Offsite-Backup war es mir, dass es verschlüsselt ist, so dass ich es auch bei einem der Cloud-Backup-Provider ohne große Bedenken hochladen konnte. Das initiale Backup mit Borg hat übrigens etwa 7h gedauert. Das anschließende Hochladen zu Backblaze über einen Uplink von 40 Mbit/s hat dann nochmal etwa 18h in Anspruch genommen. Für Leute mit schmalen Uplink ist so ein Upload natürlich leider nichts.
Was fehlt?
Eins fehlt noch: das vollständige Restore des Backups. Das habe ich noch nicht getestet, da das doch noch etwas mehr Zeit in Anspruch nimmt. Und ich bin mir ziemlich sicher, dass da einige Aspekte noch nicht vollständig gesichert sind, sodass ich an alle meine Daten wieder heran komme, wenn das Haus mit allen Geräten im schlimmsten Fall abbrennt. Da stellen sich sogar gleich mehrere Fragen:
- Habe ich alle Login-Daten für Online-Dienste gesichert? (Keepassx Backup!)
- Habe ich alle 2FA-Tokens? (Smartphone kaputt und/oder Backup-2FA-Codes im Backup wäre ungünstig)
- Habe ich das Keyfile des Borg-Archivs separat gesichert? (Im Backup das File zu haben, um das Backup zu entschlüsseln, wäre auch ungünstig)
- und vermutlich noch viele weitere Fragen
Ein gutes Backup-Konzept bringt letztendlich nichts, wenn man es nicht wiederherstellen kann. ;)