Jenkins ist eine vielgenutzte Software, welche im Zusammenhang mit kontinuierlicher Integration von Software zur Automatisierung eingesetzt wird. Jenkins wurde im Frühjahr 2016 in der Version 2.0 freigegeben, wodurch sich der Fokus vom reinen CI-Server zum generellen Automation Server änderte.
In freiesMagazin 01/2013 wurde Jenkins bereits im Bezug zur kontinuierliche Integration behandelt. Der Fokus in diesem Artikel liegt weniger auf das Thema Kontinuierliche Integration, sondern mehr auf die Neuerungen die in Version 2.0 Einzug hielten.
Dieser Artikel erschien auch in der allerletzten freiesMagazin Ausgabe 12/2016.
Jenkins-CI 1.x
Bevor es an die Neuerungen von Jenkins 2.0 geht, erfolgt zuvor noch eine Einführung in die wesentlichen Elemente und Funktionen, die sowohl in Jenkins-CI 1.x als auch in Jenkins 2.0 verfügbar sind. Jenkins ist ein Tool, womit sich viel automatisieren lässt. Es wird am häufigsten im Rahmen der kontinuierlichen Integration genutzt, um regelmäßig das Software-Projekt zu bauen, zu testen und ein Release-Paket zu schnüren.
Einfach ausgedrückt ist Jenkins eine Oberfläche, womit sich regelmäßige Aktionen verwalten und ausführen lassen. Man könnte fast sagen, dass es eine aufgeblähte Cron-Oberfläche ist, aber das stimmt natürlich so nicht ganz.
In Jenkins lassen sich sogenannte Jobs definieren, dessen Hauptbestandteil häufig Shell-Skripte sind. Ein solcher Jenkins-Job teilt sich in sechs Teile auf. Der erste Teil sind die allgemeinen Einstellungen des Jobs, in denen etwa der Name und eine Beschreibung des Jobs spezifiziert werden kann. Der zweite Teil ist das Source-Code-Management. Dort wird angegeben, an welchem Ort der Code des Projektes liegt. Jenkins unterstützt nativ und durch den Einsatz diverser Plug-ins zahlreiche Versionskontrollsysteme wie CVS, Subversion und auch Git. Es lassen sich sowohl die Quelle angeben, als auch mögliche Branches, die ausgecheckt werden sollen.
Nachdem man diese beiden Einstellungen getätigt hat, folgt die eigentliche Konfiguration des Builds. Wie zuvor erwähnt, kann man Jenkins auch ein wenig mit Cron vergleichen, da regelmäßig Jobs ausgeführt werden können. Wie und wann die Jobs ausgeführt werden, kann im Build-Auslöser Schritt definiert werden. Ein einfache Möglichkeit ist die Ausführung zu bestimmten Uhrzeiten, diese verwendet sogar die Cron-Syntax. Damit lassen sich etwa Nightly-Builds umsetzen, bei denen die Jenkins-Jobs einmal in der Nacht ausgeführt werden. Alternativ ist es ebenfalls möglich bei jedem neuen Commit das Projekt zu bauen oder im Nachgang eines Vorgänger-Jenkins-Jobs.
Der eigentliche Ablauf wird im Buildverfahren abgebildet. Dies sind häufig Shell-Skripte unter Linux- und BSD-Systemen und Batch unter Windows. Durch den Einsatz von Plug-ins lassen sich einige Build-Schritte im Build-Verfahren auch ohne Skripte lösen, das kommt dann jeweils auf die Projekt-Art und Programmiersprache an. Statt Skripte sind dort dann Formular-Felder enthalten, die man ausfüllen muss. Im Build-Verfahren wird bei einem Software-Projekt häufig das Projekt zuerst gebaut und anschließend die geschriebenen Tests ausgeführt. Sofern bei beiden Schritten kein fataler Fehler auftritt, sollten die Test-Ergebnisse als XML-Dateien herausgeschrieben werden, die in den Post-Build-Aktionen von Jenkins ausgewertet werden. Das ist somit auch der letzte Schritt, bei dem nicht nur die Test-Auswertung stattfinden kann, sondern die Ergebnisse auch per Jabber, E-Mail oder sonstigem Kommunikationsmittel versandt werden können.
Im definierten und ausgeführten Job kann man nach der Ausführung des Jobs den Status sehen. Falls das Projekt erfolgreich gebaut und die Tests fehlerfrei ausgeführt wurden, ist der Status des Jobs „Erfolgreich“, was mit einer blauen Kugel dargestellt wird. Auch gelbe bei instabilen Jobs mit einigen fehlgeschlagenen Tests oder rote Kugeln bei fehlgeschlagenen Jobs sind möglich. Der Job zeigt mehr oder weniger übersichtlich an, welche Tests fehlschlagen sind, seit wann diese Tests fehlschlagen und auch einen übersichtlichen Graphen mit der Anzahl und Ergebnisse der Tests.
Jenkins lässt sich vielfältig einsetzen und das nicht nur zur Ausführung von Builds und Tests von Projekten. Die größte Stärke liegt in den zahlreichen Erweiterungsmöglichkeiten mittels Plug-ins. Jenkins-Jobs laufen auf einem Jenkins-Knoten – welche auch häufig Jenkins-Slaves oder Build-Executors genannt werden – und diese können auf allen gängigen Betriebssystemen laufen, da letztendlich fast nur Java auf den Slaves gebraucht wird.
Jenkins hat immer zwei aktuelle Versionen: eine LTS-Version und eine normale Version. Die normale Version folgt einem wöchentlichen Rhythmus und ist die „Bleeding Edge“-Version. Diese sollte man nicht im produktiven Einsatz verwenden, da dort häufig noch viele Fehler enthalten sind. Stattdessen sollte man lieber zur LTS-Version greifen, die einen stabilen Stand darstellt und alle drei bis vier Monate auf Basis der Nicht-LTS-Version gebaut wird. Je nachdem, wie intensiv man Jenkins nutzt, passiert es auch schnell, dass viele Funktionen in Plug-ins genutzt werden, die nochmal separat aktualisiert werden müssen. Dafür gibt es auch eine eigene Plug-in-Verwaltung, die installierbare und aktualisierbare Plug-ins auflistet.
Jenkins 1.x hatte einige Nachteile, die in Jenkins 2.0 ausgemerzt werden sollten. Ein Punkt war, dass die initiale Konfiguration von Jenkins durchaus zeitaufwendig und wenig intuitiv war. In der Standard-Installation war der Server nämlich komplett offen und frei zugänglich. So konnte jeder ohne irgendeine Authentifizierung Jobs anlegen und auf dem Server laufen lassen. Die Absicherung mit Vergabe von passenden Rechten war für Jenkins-Einsteiger eher schwierig und umständlich, was den Einstieg deutlich erschwerte.
Ein weiterer wesentlicher Nachteil von den oben vorgestellten „Free Style“-Jenkins-Jobs ist, dass die Konfiguration der Jobs vollständig auf dem Jenkins-Master gespeichert ist. Die Jobs sind aber in der Regel abhängig von dem Code, der im Source-Code-Management-System hinterlegt ist. Einzelne Teil der Job-Konfiguration ließen sich zwar im Repository speichern und ausführen, aber eben nicht alles und schön war dies auch nicht sonderlich. Das Problem ist insbesondere, dass keine Versionierung erfolgte und man über die Zeit gegebenenfalls keine älteren Stände mittels Jenkins bauen konnte, außer, wenn die alten Jobs gesichert wurden. Das war in der Regel wenig komfortabel und wurde über die Zeit meist unübersichtlich.
Außerdem war auch die Konfiguration von Jenkins-Jobs mit steigender Komplexität von Projekten immer aufwändiger. Wenn man etwa in einem Projekt mehrere Branches hatte, bei denen die gleichen Jobs mit einigen Änderungen ausgeführt werden sollten, dann musste der Job mehrfach kopiert werden und bei Änderungen, die jeden Job betrafen, musste jeder Job einzeln angepasst werden. Das machte die Jenkins-Konfiguration weder einfach, noch machte es Spaß. Diese drei Punkte waren die wesentlichen Punkte, die in Jenkins 2.0 verbessert werden sollten.
Jenkins 2.0
Jenkins 2.0 erschien im Frühjahr 2016. Die erste LTS-Version 2.7 erfolgte ein paar Monate später im Sommer. Jenkins wurde vom CI-Server zum reinen Automation Server umgenannt, da Jenkins schon länger nicht mehr nur als reiner CI-Server diente. Auch die URL des Projektes änderte sich von jenkins-ci.org zu jenkins.io.
Viele Nachteile und Umständlichkeiten wurden in Jenkins 2.0 verbessert. Das wohl größte Feature ist die Nutzung von sogenannten „Pipelines“, die als Code in einer Datei gespeichert und mit dem restlichen Code des Projektes versioniert werden. Diese Features wurden größtenteils in Plug-ins implementiert, die getrennt vom eigentlichen Jenkins aktualisiert werden. Pipelines sollen nicht nur bei der Continuous Integration unterstützten, sondern auch beim Continuous Delivery, also beim Ausliefern und Ausrollen von Software.
Die ursprünglich komplett offene Basis-Installation wurde dadurch abgesichert, indem beim ersten Start von Jenkins sich zuerst ein Einrichtungsassistent öffnet, der nicht nur Basis-Plug-ins zur Installation anbietet, sondern auch einen Nutzer-Account erstellt und die Rechte entsprechend setzt.
Weitere nützliche Features sind die Einführung des „GitHub Organization Plugin“ und des „Multibranch-Pipeline“. Aber dazu später mehr.
Pipeline as Code
„Pipeline as Code“ wird das Verfahren genannt, womit die komplette Konfiguration eines Jenkins-Jobs in einer Datei geschrieben werden kann. Eine Pipeline kann man als Workflow ansehen, bei dem verschiedene Schritte ausgeführt werden, um Dinge zu erledigen. Das beinhaltet bei einem Software-Projekt etwa das Bauen, Testen und ggf. auch das Veröffentlichen und Deployen der Software.
Das Skript wird in Groovy geschrieben und in der Regel mit dem Dateinamen
Jenkinsfile im Repository abgespeichert. Alleine das Versionieren im
Repository bringt schon einen Vorteil, so kann ohne Probleme ein älterer
Stand des Repositorys ausgecheckt werden und das Projekt in Jenkins mit der
damaligen Konfiguration gebaut werden. Bei der Nutzung von Jenkins ohne
Pipelines war dies nicht möglich, da die Skripte separat im Job definiert
wurden und in der Regel nicht mit dem Projekt synchronisiert wurden.
Mit einem Jenkinsfile soll die komplette Konfiguration eines oder mehrerer Jobs in einem Jenkinsfile zusammenfließen. Wo man vorher ggf. mehrere einzelne Jobs definiert hat, die verschiedene Dinge erledigen, kann das nun in einer Pipeline und somit in einem Jenkins-Job geschehen. Pipelines haben aber auch noch weitere Vorteile, so können Pipelines beliebig pausiert werden und auch einen Neustart des Jenkins-Masters „überleben“ – egal, ob es geplant oder ungeplant war. Dies ist insbesondere bei Updates nützlich, denn Updates von Jenkins selbst und der Jenkins-Plug-ins erfordern einen Neustart des Dienstes, was nur geht, wenn keine Jobs laufen oder diese sich pausieren lassen. Bei kleinen Jenkins-Installationen, bei denen nur wenige Jobs definiert sind und nur selten Jobs angestoßen werden, ist das wohl kein großer Vorteil. Bei großen Installation mit zahlreichen parallel laufenden Jobs schon eher.
Um mit Pipelines sinnvoll arbeiten zu können, gibt es drei Begriffe die bekannt sein müssen: Steps, Nodes und Stages. Ein Step ist nicht viel mehr als eine Task, die einen Teil einer Ausführung darstellt. Sie sagt Jenkins quasi, was zu tun ist. Nodes sind generell die vorher bekannten Jenkins-Slaves, also Rechner, auf denen Jenkins-Jobs ausgeführt werden können. Im Pipeline-Kontext haben diese eine etwas andere zusätzliche Bedeutung. In einem Jenkinsfile können ein oder mehrere Node-Blöcke definiert werden. Jeder Node-Block wird zur Jenkins-Build-Queue hinzugefügt, wodurch diese an passende Nodes verteilt werden. Dort wird dann zusätzlich der Workspace vorbereitet, in dem häufig auch das Repository geklont bzw. ausgecheckt wird. So kann man in einem Jenkinsfile beispielsweise hundert Nodes definieren, die gegen einen zentralen Server Requests schicken und die Antworten auswerten. Dies ging vorher zwar schon mit Multikonfigurationsprojekten, doch war es dort auch etwas umständlicher.
Der letzte Teil ist ein Stage. Eine Pipeline kann aus mehreren Stages bestehen, die eigene Aufgaben erledigen. Um das Beispiel mit dem Bauen und Testen eines Software-Projektes fortzuführen, kann man etwa drei Stages definieren: einen zum Bauen, einen zum Testen und eine zur Testauswertung des Projektes. Die Stages werden auch noch schöner im Job definiert, sodass man sieht wie lange ein Stage in etwa dauert und ob dort etwas schief gegangen ist.
Eine Pipeline schreiben
Bislang wurde rein die Theorie der Pipeline behandelt. Spannender wird es,
wenn eine Pipeline geschrieben wird. Voraussetzung ist eigentlich nur, dass
ein Jenkins-Server mit dem Pipeline-Plug-in installiert ist. Anschließend
muss über das Hauptmenü Element anlegen eine Pipeline ausgewählt werden,
die dann ein passenden Pipeline-Job anlegt. Für den Anfang ist es immer
besser, die Pipeline innerhalb eines Jobs zu definieren, statt sie direkt in
ein Repository zu legen, da sonst sehr häufig bei Änderungen für Kleinigkeiten
eingecheckt werden muss.
Das folgende Beispiel zeigt eine ganz einfache Pipeline, die nicht viel mehr macht als die Ausgabe von „Hello World!“:
node {
echo 'Hello World!'
}
Dieses zugegeben einfache Beispiel führt auf einem beliebigen Node zur
Ausgabe von „Hello World!“. Man kann node auch noch einen Parameter
übergeben, welcher den Namen des Nodes darstellt, auf dem der Code
ausgeführt werden soll. Das sieht etwa so aus:
node("ubuntu1604") {
echo 'Hello World from Ubuntu!'
}
Damit das auch ausgeführt wird, muss allerdings ein Node existieren, mit dem
Namen oder Label ubuntu1604. Ansonsten wartet die Pipeline ewig, bis ein
solcher Node verfügbar ist.
An dieser Stelle wäre es zwar möglich die theoretisch die komplette Pipeline-Syntax
herunterzuschreiben, allerdings wäre das wohl etwas viel. Ein
wichtige Quelle um die richtige Syntax zu lernen und alle Funktionen zu finden,
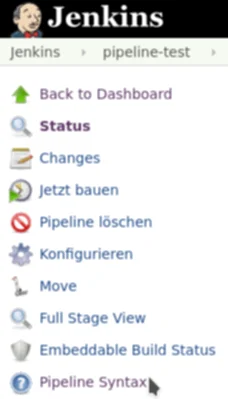
ist der „Snippet Generator“. Dieser ist in jedem Pipeline-Job zu finden, wenn man
im Hauptmenü auf Pipeline Syntax klickt.
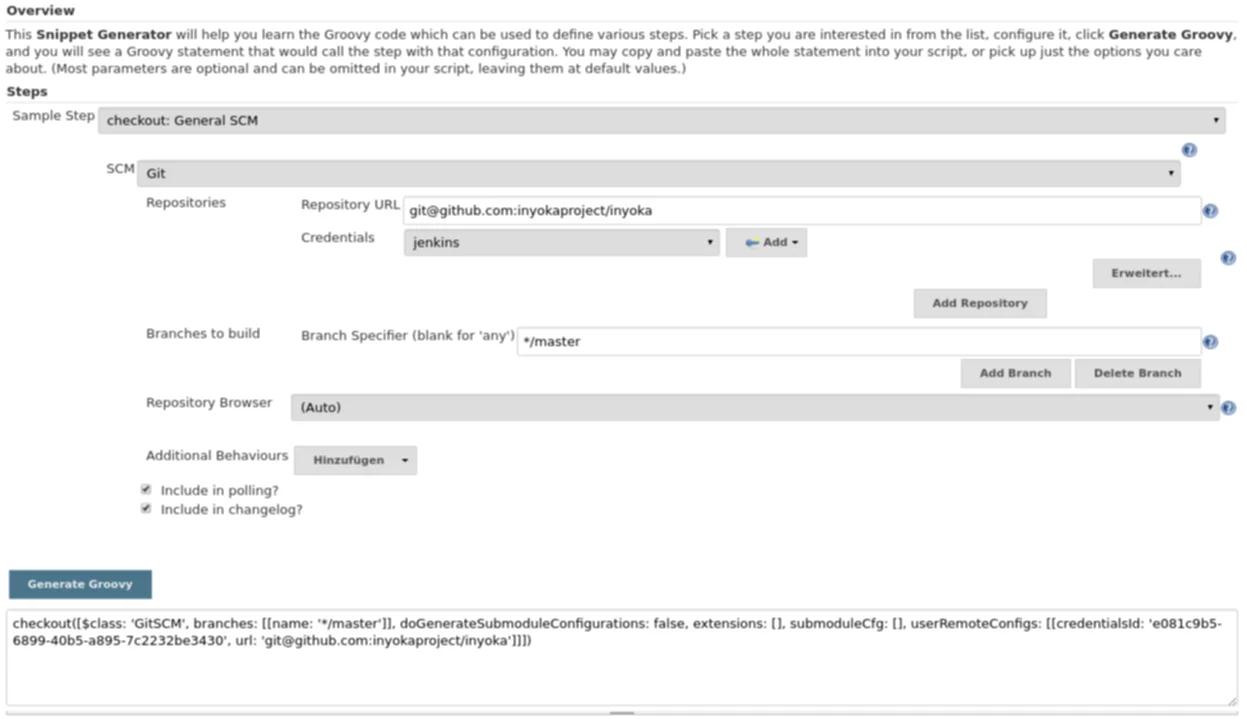
Dort findet sich ein Drop-Down-Menü, in dem sich verschiedene Build-Schritte und Aktionen über diverse Formulare zusammengeklickt werden können. Dies ist sehr oft sehr hilfreich, weil man auch nach längeren Arbeiten mit der Pipeline-Syntax sich diese nicht so einfach einprägen kann. Das liegt auch daran, dass viele Plug-ins ihre eigenen Befehle und Parameter mitbringen, die man sich fast unmöglich merken kann. Ansonten gilt, dass der Code in Groovy geschrieben wird und dessen Sprachelemente ebenfalls genutzt werden können.
Interessant werden Pipelines, wenn mehrere Stages existieren, welche die Ausführung der Pipeline sinnvoll gruppieren:
node {
stage('Checkout') {
checkout scm
}
stage('Build') {
sh '''cmake .
make -j2'''
}
stage('Tests') {
sh './run_tests'
}
}
Durch die Umsetzung der Jobs in Pipelines wurden viele Nachteile aus Jenkins 1.x ausgebessert. Einige Features sind allerdings noch nicht – oder nur anders – mit Pipelines möglich. So lassen sich aktuell etwa keine Stages innerhalb von Stages schachteln. Es existiert auch keine direkte Möglichkeit, um Multikonfigurationsprojekte umzusetzen. Letzteres sind Jobs, die mit verschiedenen Konfigurationen ausgeführt werden, also etwa Tests einer Software mit verschiedenen Einstellungen. Dies ist etwa dann notwendig, wenn man die Software über verschiedene Linux-Distributionen oder gar Betriebssystemen hinweg testet, und trotzdem noch übersichtlich sehen will, ob ein bestimmtes System noch Probleme hat.

Je nachdem wie intensiv man Jenkins nutzt, kann es also durchaus sein, dass sich noch nicht alle bisherigen Jobs in Pipelines umsetzen lassen. Da muss man wohl noch auf einige weitere Features und Verbesserungen warten. Pipelines bilden trotzdem die wesentliche Grundlage für die zukünftige Nutzung von Jenkins. Sie sind nicht unbedingt einfach zu schreiben, lassen sich durch die Nutzung des Snippet-Generators trotzdem mit vielen kleinen Schritten schreiben. Pipelines sind auch wesentlicher Bestandteil der nächsten drei Funktionen, die vorgestellt werden.
Multibranch-Pipeline
Ein weiterer Nachteil bei Jenkins 1.x war, dass man für so gut wie jeden Branch einen eigenen Job brauchte, wenn dieser gebaut und getestet werden sollte. Dadurch, dass man ein Jenkinsfile geschrieben hat, liegt die Konfiguration des Jobs schon im Repository, was an dieser Stelle einfach genutzt werden kann für jeden Branch, den man haben möchte. Theoretisch kann man auch weiterhin einzelne Jobs für einzelne Branches anlegen, die dann jeweils das Jenkinsfile anlegen. Aber auch das wäre eher umständlich, da nicht benötigte Entwicklungsbranches mit ihren Jobs immer wieder gelöscht werden müssen. Hier kommt das Multibranch-Pipeline-Plug-in ins Spiel. In dem Job definiert man nur, welches Repository eingelesen werden soll. Anschließend scannt Jenkins das komplette Repository, um alle Branches mit einem Jenkinsfile zu finden. Daraus erzeugt Jenkins dann dynamisch eigene Jobs, was viel Konfigurations- und Wartungsarbeit verhindert. Bei gelöschten Branches löscht Jenkins automatisch auch den dynamisch generierten Job.
Wesentlicher Nachteil dieser Lösung ist, dass jedes Repository einzeln konfiguriert werden muss. Dafür gibt es aber auch eine Lösung, jedenfalls für GitHub.
GitHub Organization Folder Plugin
Das „GitHub Organization Folder Plugin“ geht das Problem an, dass man für jedes Repository ein eigenen Job anlegen muss, wovon dann die Jenkinsfiles eingelesen werden. Mit diesem Plug-in wird nicht nur ein Repository, sondern die ganze GitHub-Organisation gescannt. Jenkins legt dann einen Ordner an, in dem alle Repositorys mit allen Branches, die ein Jenkinsfile enthalten, aufgelistet werden. Weiterhin konfiguriert Jenkins ebenfalls das automatische Bauen bei Pull-Requests. Zuvor muss Jenkins die entsprechenden Rechte für die GitHub-Organisation gegeben werden, damit dieser den Pull-Request auslesen darf. GitHub-Organisation umfasst dabei nicht nur die Organisationen von GitHub, sondern auch normale Benutzer-Accounts.
Das Plug-in erleichtert die Einrichtung von GitHub-Repositorys einer Organisation in Jenkins deutlich, da eine Konfiguration von einzelnen Repositorys und Pull-Requests nicht notwendig ist. Dies ist im Zusammenhang mit der erleichterten initialen Einrichtung ein weiteres Feature, was die Konfiguration und Administrierung deutlich erleichtert, da das meiste automatisch und dynamisch erzeugt wird.
Leider gibt es diese Funktion nur für GitHub. Für andere Git-Hostingdienste ist es leider nicht verfügbar, könnte aber theoretisch mit den nötigen Kenntnissen selbst implementiert werden, wenn APIs auf der Gegenstelle verfügbar sind.
Blue Ocean
Die Web-Oberfläche von Jenkins funktioniert zwar prinzipiell, ist allerdinga an vielen Stellen nicht besonders benutzerfreundlich und auch nicht mehr auf Höhe der Zeit. Blue Ocean nennt sich das Projekt, welches eine neue, frische und moderne Oberfläche für Jenkins bringen soll und speziell für Pipelines optimiert ist.
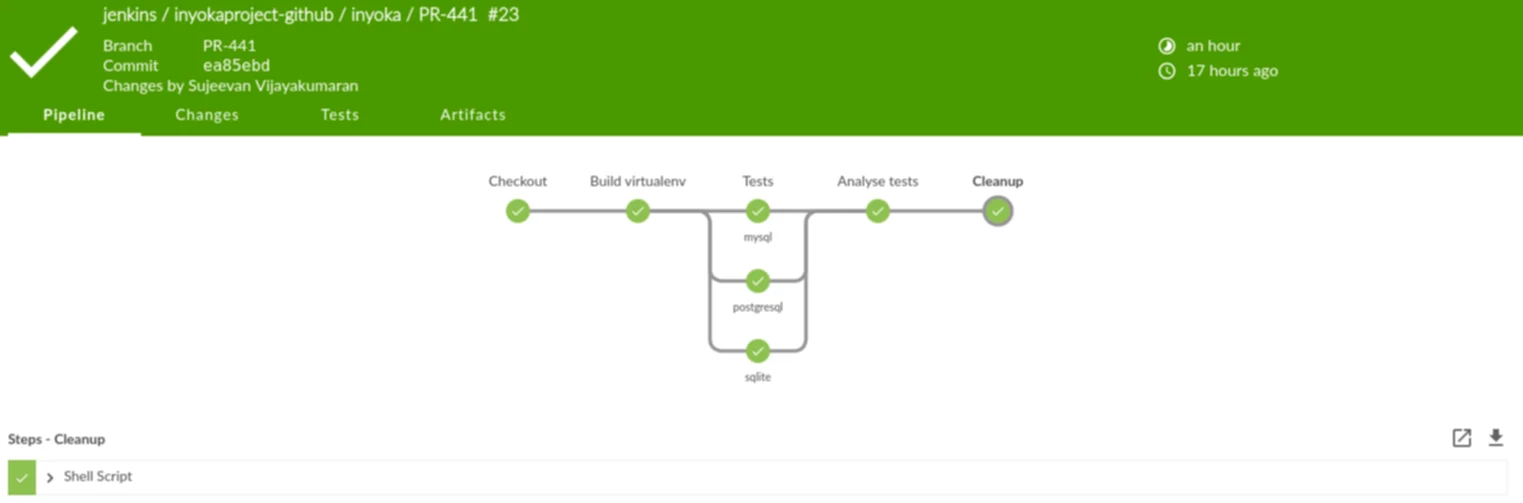
Zur Zeit befindet sich Blue Ocean in einer Beta-Phase für die erste Version und kann noch recht wenig. Blue Ocean wird wie so vieles von Jenkins in Plug-ins entwickelt und ausgeliefert. Im Moment kann es vor allem eins: Jobs alphabetisch auflisten und den Build-Status mit Konsolen-Ausgaben von Pipelines übersichtlich darstellen.
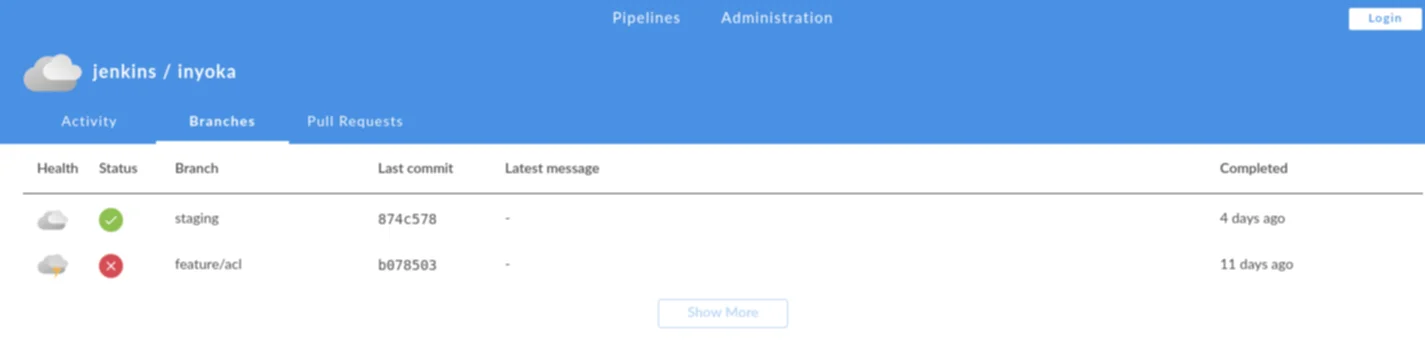
Für den alltäglichen Betrieb stößt man bei Blue Ocean schnell an seine Grenzen, da vieles nicht möglich oder noch nicht zur Verfügung steht. Allen vorran lassen sich keine administrative Dinge erledigen. Das betrifft nicht nur die Jenkins-Server-Konfiguration, sondern auch die Konfiguration und das Anlegen von Jobs. In Zukunft werden in Blue Ocean mehr und mehr Funktionen einfließen – und dabei nicht nur Funktionen der altbewährten Oberfläche. Später sollen sich Pipelines auch einfacher und hübscher über Blue Oceans anlegen lassen. Bis es allerdings soweit ist, dürfte es noch einige Zeit dauern. Immerhin läuft Blue Ocean unter einer eigenen URL und lässt sich parallel zum Standard installieren und nutzen.
Fazit
Mit Jenkins 2.0 wurden einige Neuerungen eingeführt, die das tägliche Nutzen von Jenkins angenehmer gestalten und einige neue Nutzungsmöglichkeiten bringen. Mit Blue Ocean wird zudem an einer frischen Oberfläche gearbeitet, die Einiges angenehmer und hübscher macht. Es gibt allerdings auch viele Alternativen wie GitLab CI oder Travis-CI, die auch einzelne Vor- und Nachteile jeweils haben.